Parsing data with BeautifulSoup¶
!pip install bs4
Requirement already satisfied: bs4 in /Users/mac/.pyenv/versions/3.7.0/lib/python3.7/site-packages (0.0.1) Requirement already satisfied: beautifulsoup4 in /Users/mac/.pyenv/versions/3.7.0/lib/python3.7/site-packages (from bs4) (4.10.0) Requirement already satisfied: soupsieve>1.2 in /Users/mac/.pyenv/versions/3.7.0/lib/python3.7/site-packages (from beautifulsoup4->bs4) (2.2.1) [notice] A new release of pip is available: 23.0.1 -> 23.3.1 [notice] To update, run: pip install --upgrade pip
#import
import requests
from bs4 import BeautifulSoup
page = requests.get("http://dataquestio.github.io/web-scraping-pages/simple.html")
#let's feed the webpage to the parser
soup = BeautifulSoup(page.content, 'html.parser')
soup
<!DOCTYPE html> <html> <head> <title>A simple example page</title> </head> <body> <p>Here is some simple content for this page.</p> </body> </html>
Pour le moment rien de bien différent. En fait, les tags sont organisés en hiérachie, ou en tree, comme vu dans le cours théorique. Chaque tag est appelé node (noeud). Le noeud le plus haut est <html>, puis suivent ses children <head> et <body>, au même niveau.
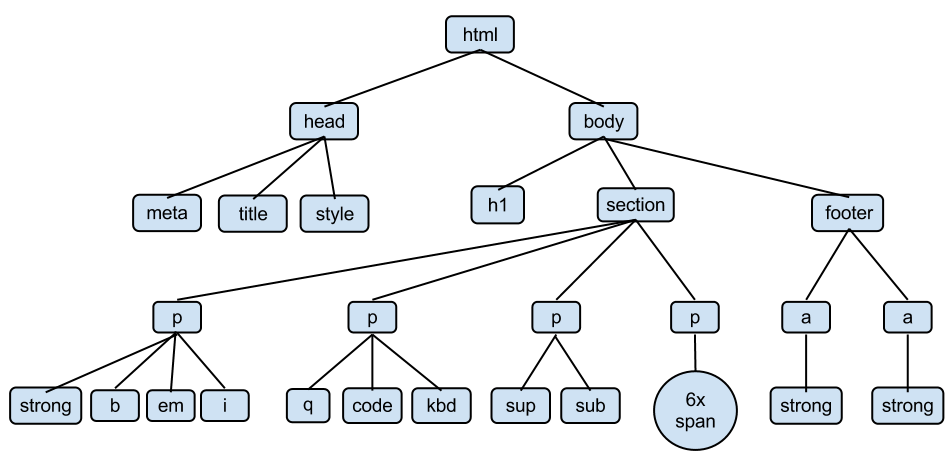
A l'intérieur de <head> se trouve les informations sur la page, pas visible pour un utilisateur lambda sur son navigateur. A l'intérieur de <body> se trouve le contenu visible pour les utilisateurs. Les enfants de <body> sont <h1> (un titre), <section> (littéralement : une section qui contient des paragraphes de texte <p>), et un <footer> (qui contient des liens <a>).
#bs dispose d'une méthode pour afficher le HTML de façon bien indentée
print(soup.prettify())
<!DOCTYPE html> <html> <head> <title> A simple example page </title> </head> <body> <p> Here is some simple content for this page. </p> </body> </html>
Find elements with tags¶
La fonctionnalité la plus importante de bs est la possibilité de saisir directement les éléments encapsulés dans un tag spécifique.
soup.find('p')
<p>Here is some simple content for this page.</p>
Attention : find ne récupère que le premier tag qui remplit la condtion. Pour obtenir tous les tags de l'arbre remplissant la condition, il faut utiliser find_all. Le résultat est sous forme de liste :
soup.find_all('p')
[<p>Here is some simple content for this page.</p>]
Une autre méthode importante de bs est .get_text(), pour extraire les données exploitables
soup.find('p').get_text()
'Here is some simple content for this page.'
# use the .strip() string method to remove leading and trailing characters
soup.find('p').get_text().strip()
'Here is some simple content for this page.'
#.get_text ne marche que sur les tags uniques, pas sur une liste résultant d'un 'find_all'
#Il faut donc slicer
soup.find_all('p')[0].get_text()
'Here is some simple content for this page.'
Loop through tag, class and id¶
#chargeons une page plus un peu plus complexe
page = requests.get("http://dataquestio.github.io/web-scraping-pages/ids_and_classes.html")
soup = BeautifulSoup(page.content)
soup.find_all('p')
[<p class="inner-text first-item" id="first">
First paragraph.
</p>, <p class="inner-text">
Second paragraph.
</p>, <p class="outer-text first-item" id="second">
<b>
First outer paragraph.
</b>
</p>, <p class="outer-text">
<b>
Second outer paragraph.
</b>
</p>]
print(soup.prettify())
<html>
<head>
<title>
A simple example page
</title>
</head>
<body>
<div>
<p class="inner-text first-item" id="first">
First paragraph.
</p>
<p class="inner-text">
Second paragraph.
</p>
</div>
<p class="outer-text first-item" id="second">
<b>
First outer paragraph.
</b>
</p>
<p class="outer-text">
<b>
Second outer paragraph.
</b>
</p>
</body>
</html>
On peut voir que les paragraphes <p> ont une class et un id. On peut s'en servir pour trouver nos informations plus précisément.
soup.find_all('p', {"class":"outer-text"})[0].get_text().strip()
'First outer paragraph.'
soup.find_all('p', {"class":"outer-text", "id":"second"})[0].get_text().strip()
'First outer paragraph.'
# un id étant unique en HTML, on peut y accéder directement sans mentionner le tag
soup.find(id="first")
<p class="inner-text first-item" id="first">
First paragraph.
</p>
Avec la méthode find_all et la syntaxe de dictionnaires, on peut chercher des tags selon leurs noms d'attribut (pas seulement class et id, les plus communs, mais tous les attributs existant, qui peuvent prendre bien des noms selon le site internet en question).
Crawling Wikipedia¶
Nous voulons en apprendre plus sur la science de données, il est donc tout naturel de charger la page wikipedia sur la science de données pour trouver tous les articles cités par la page.
wikipedia_DS_url = "https://fr.wikipedia.org/wiki/Science_des_donn%C3%A9es"
wiki_raw = requests.get(wikipedia_DS_url)
soup = BeautifulSoup(wiki_raw.content)
str(soup)[:1000]
'<!DOCTYPE html>\n<html class="client-nojs vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-sticky-header-disabled vector-feature-page-tools-pinned-disabled vector-feature-toc-pinned-clientpref-1 vector-feature-main-menu-pinned-disabled vector-feature-limited-width-clientpref-1 vector-feature-limited-width-content-enabled vector-feature-zebra-design-enabled vector-feature-custom-font-size-clientpref-0 vector-feature-client-preferences-disabled vector-feature-client-prefs-pinned-disabled vector-feature-typography-survey-disabled vector-toc-available" dir="ltr" lang="fr">\n<head>\n<meta charset="utf-8"/>\n<title>Science des données — Wikipédia</title>\n<script>(function(){var className="client-js vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-sticky-header-disabled vector-feature-page-tools-pinned-disabled vector-feature-toc-pinned-clientpref-1 vector-feature-main-menu-pi'
La soup est un peu plus conséquente n'est-ce pas ?
On veut en extraire les liens vers d'autres articles, pour pouvoir élargir nos connaissances en data science. On commence par inspecter la page wikipedia dansnotre navigateur, on découvre que c'est le tag <main> qui nous intéresse.
main_soup = soup.find("main") # pas besoin de find_all car il n'y a qu'un main
str(main_soup)[:1000]
'<main class="mw-body" id="content" role="main">\n<header class="mw-body-header vector-page-titlebar">\n<nav aria-label="Sommaire" class="vector-toc-landmark" role="navigation">\n<div class="vector-dropdown vector-page-titlebar-toc vector-button-flush-left" id="vector-page-titlebar-toc">\n<input aria-haspopup="true" aria-label="Basculer la table des matières" class="vector-dropdown-checkbox" data-event-name="ui.dropdown-vector-page-titlebar-toc" id="vector-page-titlebar-toc-checkbox" role="button" type="checkbox"/>\n<label aria-hidden="true" class="vector-dropdown-label cdx-button cdx-button--fake-button cdx-button--fake-button--enabled cdx-button--weight-quiet cdx-button--icon-only" for="vector-page-titlebar-toc-checkbox" id="vector-page-titlebar-toc-label"><span class="vector-icon mw-ui-icon-listBullet mw-ui-icon-wikimedia-listBullet"></span>\n<span class="vector-dropdown-label-text">Basculer la table des matières</span>\n</label>\n<div class="vector-dropdown-content">\n<div class="vector-unpi'
On va extraire les liens dans cette soup. Les liens sont contenus dans les blocs a
links = main_soup.find_all("a")
Ce n'est pas encore satisfaisant car certains liens ne renvoient pas vers des articles. On a besoin de garder seulement les <a> qui contiennent un attribut href (où l'on trouve le texte réel du lien) et un attribut title (qui correspond aux liens vers les autres articles).
links = main_soup.find_all("a", href=True, title=True)
links[:10]
[<a class="interlanguage-link-target" href="https://ar.wikipedia.org/wiki/%D8%B9%D9%84%D9%85_%D8%A7%D9%84%D8%A8%D9%8A%D8%A7%D9%86%D8%A7%D8%AA" hreflang="ar" lang="ar" title="علم البيانات – arabe"><span>العربية</span></a>, <a class="interlanguage-link-target" href="https://az.wikipedia.org/wiki/Veril%C9%99nl%C9%99r_elmi" hreflang="az" lang="az" title="Verilənlər elmi – azerbaïdjanais"><span>Azərbaycanca</span></a>, <a class="interlanguage-link-target" href="https://bg.wikipedia.org/wiki/%D0%9D%D0%B0%D1%83%D0%BA%D0%B0_%D0%B7%D0%B0_%D0%B4%D0%B0%D0%BD%D0%BD%D0%B8%D1%82%D0%B5" hreflang="bg" lang="bg" title="Наука за данните – bulgare"><span>Български</span></a>, <a class="interlanguage-link-target" href="https://bn.wikipedia.org/wiki/%E0%A6%89%E0%A6%AA%E0%A6%BE%E0%A6%A4%E0%A7%8D%E0%A6%A4_%E0%A6%AC%E0%A6%BF%E0%A6%9C%E0%A7%8D%E0%A6%9E%E0%A6%BE%E0%A6%A8" hreflang="bn" lang="bn" title="উপাত্ত বিজ্ঞান – bengali"><span>বাংলা</span></a>, <a class="interlanguage-link-target" href="https://ca.wikipedia.org/wiki/Ci%C3%A8ncia_de_les_dades" hreflang="ca" lang="ca" title="Ciència de les dades – catalan"><span>Català</span></a>, <a class="interlanguage-link-target" href="https://cs.wikipedia.org/wiki/Data_science" hreflang="cs" lang="cs" title="Data science – tchèque"><span>Čeština</span></a>, <a class="interlanguage-link-target" href="https://de.wikipedia.org/wiki/Data_Science" hreflang="de" lang="de" title="Data Science – allemand"><span>Deutsch</span></a>, <a class="interlanguage-link-target" href="https://el.wikipedia.org/wiki/%CE%95%CF%80%CE%B9%CF%83%CF%84%CE%AE%CE%BC%CE%B7_%CE%B4%CE%B5%CE%B4%CE%BF%CE%BC%CE%AD%CE%BD%CF%89%CE%BD" hreflang="el" lang="el" title="Επιστήμη δεδομένων – grec"><span>Ελληνικά</span></a>, <a class="interlanguage-link-target" href="https://en.wikipedia.org/wiki/Data_science" hreflang="en" lang="en" title="Data science – anglais"><span>English</span></a>, <a class="interlanguage-link-target" href="https://eo.wikipedia.org/wiki/Datum-scienco" hreflang="eo" lang="eo" title="Datum-scienco – espéranto"><span>Esperanto</span></a>]
C'est mieux : mais il ya encore des éléments wikidata qui ne nous intéresse pas. Il faut être encore plus sélectif. On remarque que les liens vers des articles commencent par /wiki/.
#utilisons la méthode startswith
'Bonjour'.startswith("a")
False
#meme méthode en utilisant une fonctions lambda
links = main_soup.find_all("a", href=lambda link: link and link.startswith("/wiki/"), title=True)
print(links[:5])
[<a accesskey="c" href="/wiki/Science_des_donn%C3%A9es" title="Voir le contenu de la page [c]"><span>Article</span></a>, <a accesskey="t" href="/wiki/Discussion:Science_des_donn%C3%A9es" rel="discussion" title="Discussion au sujet de cette page de contenu [t]"><span>Discussion</span></a>, <a accesskey="j" href="/wiki/Sp%C3%A9cial:Pages_li%C3%A9es/Science_des_donn%C3%A9es" title="Liste des pages liées qui pointent sur celle-ci [j]"><span>Pages liées</span></a>, <a accesskey="k" href="/wiki/Sp%C3%A9cial:Suivi_des_liens/Science_des_donn%C3%A9es" rel="nofollow" title="Liste des modifications récentes des pages appelées par celle-ci [k]"><span>Suivi des pages liées</span></a>, <a accesskey="u" href="/wiki/Aide:Importer_un_fichier" title="Téléverser des fichiers [u]"><span>Téléverser un fichier</span></a>]
liens = []
for l in links:
liens.append(l['href'])
liens[:5]
['/wiki/Science_des_donn%C3%A9es', '/wiki/Discussion:Science_des_donn%C3%A9es', '/wiki/Sp%C3%A9cial:Pages_li%C3%A9es/Science_des_donn%C3%A9es', '/wiki/Sp%C3%A9cial:Suivi_des_liens/Science_des_donn%C3%A9es', '/wiki/Aide:Importer_un_fichier']
from urllib.parse import unquote
decoded_urls = [unquote(url) for url in liens]
for i,url in enumerate(decoded_urls):
print(url)
if i==4: break
/wiki/Science_des_données /wiki/Discussion:Science_des_données /wiki/Spécial:Pages_liées/Science_des_données /wiki/Spécial:Suivi_des_liens/Science_des_données /wiki/Aide:Importer_un_fichier
On avance ! On va maintenant stocker nos liens dans une liste pour pouvoir les utiliser plus tard
# Dans un tag, on peut accéder aux attributs avec le slicing habituel
links[0]['href']
'/wiki/Science_des_donn%C3%A9es'
list_of_article_links = [ link["href"] for link in links ]
list_of_article_links = [unquote(url) for url in list_of_article_links]; list_of_article_links[:10]
['/wiki/Science_des_données', '/wiki/Discussion:Science_des_données', '/wiki/Spécial:Pages_liées/Science_des_données', '/wiki/Spécial:Suivi_des_liens/Science_des_données', '/wiki/Aide:Importer_un_fichier', '/wiki/Spécial:Pages_spéciales', '/wiki/Science', '/wiki/Architecte_de_données', '/wiki/Donnée', '/wiki/Modèle:Infobox_Discipline']
Essayons d'accéder à ces liens
# on va récupérer le contenu du premier lien
example_url = list_of_article_links[0]
requests.get(example_url).content
--------------------------------------------------------------------------- MissingSchema Traceback (most recent call last) <ipython-input-32-c9cb1a2e7f45> in <module>() 1 # on va récupérer le contenu du premier lien 2 example_url = list_of_article_links[0] ----> 3 requests.get(example_url).content /Users/mac/.pyenv/versions/3.7.0/lib/python3.7/site-packages/requests/api.py in get(url, params, **kwargs) 71 """ 72 ---> 73 return request("get", url, params=params, **kwargs) 74 75 /Users/mac/.pyenv/versions/3.7.0/lib/python3.7/site-packages/requests/api.py in request(method, url, **kwargs) 57 # cases, and look like a memory leak in others. 58 with sessions.Session() as session: ---> 59 return session.request(method=method, url=url, **kwargs) 60 61 /Users/mac/.pyenv/versions/3.7.0/lib/python3.7/site-packages/requests/sessions.py in request(self, method, url, params, data, headers, cookies, files, auth, timeout, allow_redirects, proxies, hooks, stream, verify, cert, json) 573 hooks=hooks, 574 ) --> 575 prep = self.prepare_request(req) 576 577 proxies = proxies or {} /Users/mac/.pyenv/versions/3.7.0/lib/python3.7/site-packages/requests/sessions.py in prepare_request(self, request) 496 auth=merge_setting(auth, self.auth), 497 cookies=merged_cookies, --> 498 hooks=merge_hooks(request.hooks, self.hooks), 499 ) 500 return p /Users/mac/.pyenv/versions/3.7.0/lib/python3.7/site-packages/requests/models.py in prepare(self, method, url, headers, files, data, params, auth, cookies, hooks, json) 366 367 self.prepare_method(method) --> 368 self.prepare_url(url, params) 369 self.prepare_headers(headers) 370 self.prepare_cookies(cookies) /Users/mac/.pyenv/versions/3.7.0/lib/python3.7/site-packages/requests/models.py in prepare_url(self, url, params) 438 if not scheme: 439 raise MissingSchema( --> 440 f"Invalid URL {url!r}: No scheme supplied. " 441 f"Perhaps you meant https://{url}?" 442 ) MissingSchema: Invalid URL '/wiki/Science_des_données': No scheme supplied. Perhaps you meant https:///wiki/Science_des_données?
Malheureusement l'URL est invalide ! en effet le lien n'est pas complet. Il faut retourner sur wikipedia pour observer commment se constituent leurs URLs complètes. Il faut ajouter le préfixe "https://fr.wikipedia.org/"
prefix = "https://fr.wikipedia.org"
prefix + list_of_article_links[0] # concaténation rapide
'https://fr.wikipedia.org/wiki/Science_des_données'
first_article_content = requests.get(prefix + list_of_article_links[0]).content
first_article_content[:1000]
b'<!DOCTYPE html>\n<html class="client-nojs vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-sticky-header-disabled vector-feature-page-tools-pinned-disabled vector-feature-toc-pinned-clientpref-1 vector-feature-main-menu-pinned-disabled vector-feature-limited-width-clientpref-1 vector-feature-limited-width-content-enabled vector-feature-zebra-design-enabled vector-feature-custom-font-size-clientpref-0 vector-feature-client-preferences-disabled vector-feature-client-prefs-pinned-disabled vector-feature-typography-survey-disabled vector-toc-available" lang="fr" dir="ltr">\n<head>\n<meta charset="UTF-8">\n<title>Science des donn\xc3\xa9es \xe2\x80\x94 Wikip\xc3\xa9dia</title>\n<script>(function(){var className="client-js vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-sticky-header-disabled vector-feature-page-tools-pinned-disabled vector-feature-toc-pinned-clientpref-1 vector-feature-main-menu'
Cette fois-ci cela a marché comme on le souhaitait, on peut donc renommer nos liens en utilisant les listes en compréhension.
# Essayons de rendre nos noms de variables le plus clair possible
list_article_links_complete = [prefix + extension for extension in list_of_article_links]
list_article_links_complete[:10]
['https://fr.wikipedia.org/wiki/Science_des_données', 'https://fr.wikipedia.org/wiki/Discussion:Science_des_données', 'https://fr.wikipedia.org/wiki/Spécial:Pages_liées/Science_des_données', 'https://fr.wikipedia.org/wiki/Spécial:Suivi_des_liens/Science_des_données', 'https://fr.wikipedia.org/wiki/Aide:Importer_un_fichier', 'https://fr.wikipedia.org/wiki/Spécial:Pages_spéciales', 'https://fr.wikipedia.org/wiki/Science', 'https://fr.wikipedia.org/wiki/Architecte_de_données', 'https://fr.wikipedia.org/wiki/Donnée', 'https://fr.wikipedia.org/wiki/Modèle:Infobox_Discipline']
pd.DataFrame(list_article_links_complete, columns=['liens'])
| liens | |
|---|---|
| 0 | https://fr.wikipedia.org/wiki/Science_des_données |
| 1 | https://fr.wikipedia.org/wiki/Discussion:Scien... |
| 2 | https://fr.wikipedia.org/wiki/Spécial:Pages_li... |
| 3 | https://fr.wikipedia.org/wiki/Spécial:Suivi_de... |
| 4 | https://fr.wikipedia.org/wiki/Aide:Importer_un... |
| ... | ... |
| 322 | https://fr.wikipedia.org/wiki/Catégorie:Portai... |
| 323 | https://fr.wikipedia.org/wiki/Catégorie:Portai... |
| 324 | https://fr.wikipedia.org/wiki/Catégorie:Projet... |
| 325 | https://fr.wikipedia.org/wiki/Catégorie:Portai... |
| 326 | https://fr.wikipedia.org/wiki/Catégorie:Portai... |
327 rows × 1 columns
On a donc produit un workflow pour obtenir une liste de liens utilisables. Il nous suffirait de remettre les différentes étapes dans une fonction pour refaire le même processus sur une autre page.
Some data analysis¶
Enfin, il est possible de réaliser quelques analyses sur ces liens. Pour chaque article, on veut connaître le nombre de notes et références, pour voir si wikipedia est bien documenté...
from tqdm.notebook import tqdm # pour afficher des barres de chargement
import numpy as np # pour calculer des médianes
### Notre analyse
articles_number_notes = []
for article_link in tqdm(list_article_links_complete[:50]): # intégrer tdqm permet d'afficher une barre de progression de la boucle
# constitution de notre soup de façon classique
first_article_content = requests.get(article_link).content
first_article_soup = BeautifulSoup(first_article_content, 'html.parser')
# Certains articles n'auront ni notes ni références, ils donneront une erreur
# Ces erreurs seront gérés par la commande except
try:
# On parcourt l'arbre pour trouver les éléments dans la liste référence
notes_et_references = (first_article_soup
.find('main')
.find("ol", {"class": "references"})
.find_all("li")
)
# on stocke dans une liste le nombre de références
number_of_notes = len(notes_et_references)
articles_number_notes.append(number_of_notes)
except AttributeError:
print("No note or reference in article", article_link)
articles_number_notes.append(0) # Il n'y a pas de notes donc on ajoute 0 à la liste.
print("\nMedian number of notes per article is", np.median(articles_number_notes))
print("Mean number of notes per article is", np.mean(articles_number_notes))
print("Stdev of number of notes per article is", np.std(articles_number_notes))
HBox(children=(FloatProgress(value=0.0, max=50.0), HTML(value='')))
No note or reference in article https://fr.wikipedia.org/wiki/Discussion:Science_des_données No note or reference in article https://fr.wikipedia.org/wiki/Spécial:Pages_liées/Science_des_données No note or reference in article https://fr.wikipedia.org/wiki/Spécial:Suivi_des_liens/Science_des_données No note or reference in article https://fr.wikipedia.org/wiki/Aide:Importer_un_fichier No note or reference in article https://fr.wikipedia.org/wiki/Spécial:Pages_spéciales No note or reference in article https://fr.wikipedia.org/wiki/Architecte_de_données No note or reference in article https://fr.wikipedia.org/wiki/Modèle:Infobox_Discipline No note or reference in article https://fr.wikipedia.org/wiki/Calcul_à_haute_performance No note or reference in article https://fr.wikipedia.org/wiki/Système_de_traitement_de_l'information No note or reference in article https://fr.wikipedia.org/wiki/Tableau_de_bord_(informatique) Median number of notes per article is 9.5 Mean number of notes per article is 24.34 Stdev of number of notes per article is 36.75519555110542
L'écart-type est élevé et la moyenne est beaucoup plus haute que la médiane, ce qui dans notre cas laisse supposer que certains articles sont très documentés et pousse la moyenne et l'écart-type vers le haut. Ces articles poussés ne représentent pas la masse d'articles qui ont entre 8 et 9 références (valeur médiane).
On peut afficher les graphiques qui le montrent.
import matplotlib.pyplot as plt
plt.boxplot(articles_number_notes, patch_artist=True);

import seaborn as sns
plt.figure(figsize=(4,5))
sns.violinplot(data=articles_number_notes);
