Scrapy Introduction
Python Scrapy is a very popular Python framework specifically designed for web scraping and crawling. It has a huge amount of functionality ready to use out of the box and can be easily extendable with open-source Scrapy extensions and middlewares.
Basicaly Scrapy is a great option for building a production-ready scrapers that can scrape the web at scale.
The good part is like every other python tool scrapy has the community power, it has a lot a of free ressources, like hands on project like the scrapy playbook. We will see this later do not worry 😎
Install scrapy
First, of course you need to install the scrapy library, you can follow the official documentation or the instruction here for a complete python virtualenv installation (which I encourage you to follow in order to keep your local machine clean 🤓)
I recommend you to use an editor like visual studio code (it's the one I will be using during this example) because we need to handle many files and do not want to navigate in our terminal so often with the cd command.
First scrapy project
After setting up our virtual environment and installing Scrapy, we're ready to dive into the exciting part: creating our very first Scrapy project.
The project created by Scrapy will contain all our scraper code. Scrapy provides a predefined template to organize our scrapers efficiently.
To initiate a Scrapy project, we use the command:
For our example, as our target is the QuoteToScrape website, we'll name our project quotescraper. However, you can choose any name for your project.
After running this command, if we list the contents of our directory using the ls command, we should see:
Understanding the Structure of a Scrapy project
Let’s take a moment to understand Scrapy's project structure, particularly what the scrapy startproject bookscraper command did. If you open this folder in a code editor like VS Code, you'll see the complete directory structure:
├── scrapy.cfg
└── bookscraper
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
└── myCustomSpider.py
This structure, created by Scrapy, is the foundation for our project and highlights five key components of every Scrapy project: Spiders, Items, Middlewares, Pipelines, and Settings. These components enable the creation of a versatile scraper.
We might not use all these files in a beginner's project, but it's worth understanding each one:
settings.pyholds all project settings, such as pipeline and middleware activation, delays, and concurrency.items.pydefines a model for your scraped data.pipelines.pyprocesses items yielded by spiders, often used for data cleaning and storage.middlewares.pyis where request modifications and response handling occur.scrapy.cfgis a configuration file for deployment settings.spidersare the core component where the scraping logic resides : it's here we will spend the most of our time 😂
At this point you might have one question : why so much effort in order to scrap some information of a webpage, some key points to note:
- Asynchronous Nature: Built on the Twisted framework, Scrapy's requests are non-blocking.
- Spider Name: Each spider must have a unique name for identification.
- Start Requests: The initial URLs for scraping are defined in start_requests().
- Parse Method: This is where the response data is processed and extracted.
- Scrapy's real power lies in its Items, Middlewares, Pipelines, and Settings, which provide a more structured approach compared to a typical Python Requests/BeautifulSoup scraper.
Scrapy Items
In Scrapy, Items serve as containers for structured data that we scrape. They enable easy cleaning, validation, and storage of scraped data with features like ItemLoaders, Item Pipelines, and Feed Exporters.
Advantages of using Scrapy Items include:
- Structuring and defining a clear schema for your data.
- Simplifying data cleaning and processing.
- Validating and deduplicating data, as well as monitoring data feeds.
- Streamlining data storage and exporting with Scrapy Feed Exports.
- Facilitating the use of Scrapy Item Pipelines & Item Loaders.
Scrapy Items are typically defined in the items.py file like this :
import scrapy
class QuotescrapItem(scrapy.Item):
# define the fields for your item here like:
quote = scrapy.Field()
author = scrapy.Field()
about = scrapy.Field()
tags = scrapy.Field()
Inside your spider, instead of yielding a dictionary, you create and yield a new Item filled with the scraped data but we will see this later do not worry 🤓
Scrapy Pipelines
Pipelines in Scrapy are where the scraped data passes through for cleaning, processing, validation, and storage.
Some functions of Scrapy Pipelines:
- Clean the data (e.g., removing currency symbols from prices).
- Format the data (e.g., converting strings to integers).
- Enrich the data (e.g., converting relative links to absolute links).
- Validate the data (e.g., ensuring a scraped price is viable).
- Store data in various formats and locations.
We will see later an example of pipeline storing data in Databases.
Scrapy Middlewares
Scrapy Middlewares are components that process requests and responses within the Scrapy framework. They fall into two categories: Downloader Middlewares and Spider Middlewares.
Downloader middlewares act between the Scrapy Engine and the Downloader. They process requests going to the Downloader and responses coming back to the Engine.
Default middlewares in Scrapy are include in the settings.py file like this :
These middlewares handle a range of functions like timing out requests, managing headers, user agents, retries, cookies, caches, and response compression.
To disable any default middleware, set it to None in your settings.py.
Custom middlewares can be created for specific tasks like altering requests, handling responses, retrying requests based on content, and more.
Code our first spider
Scrapy provides a number of different spider types, however, in this article we will cover the most common one, the generic Spider. Here are some of the most common ones:
- Spider - Takes a list of start_urls and scrapes each one with a parse method.
- CrawlSpider - Designed to crawl a full website by following any links it finds.
- SitemapSpider - Designed to extract URLs from a sitemap
To create a new generic spider, simply run the genspider command:
# syntax is --> scrapy genspider <name_of_spider> <website>
$ scrapy genspider quotespider quote.toscrape.com
Then you can see that a new file is added to you spider folder inside your project and look like this :
import scrapy
class QuoteSpider(scrapy.Spider):
name = 'quotespider'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
pass
Here we see that the genspider command has created a template spider for us to use in the form of a Spider class. This spider class contains:
name- a class attribute that gives a name to the spider. We will use this when running our spider later scrapy crawl. allowed_domains- a class attribute that tells Scrapy that it should only ever scrape pages of the books.toscrape.com domain. This prevents the spider going rouge and scraping lots of websites. This is optional.start_urls- a class attribute that tells Scrapy the first url it should scrape. We will be changing this in a bit.parse- the parse function is called after a response has been recieved from the target website.
To start using this Spider we just need to start inserting our parsing code into the parse function. To do this, we need to handle our CSS/xPath selectors to parse the data we want from the page. We will use Scrapy ipython Shell to find play with selectors.
ipython scrapy Shell
To retrieve data from an HTML page, we will utilize XPath or CSS selectors. These selectors act as navigational tools guiding Scrapy through the DOM tree to pinpoint the required data.
Here we'll first employ some CSS selectors for data extraction, supported by the Scrapy Shell for crafting these selectors.
A very good feature of Scrapy is its integrated shell, which significantly aids in testing and fine-tuning your selectors. This tool allows for immediate testing of selectors in the terminal, eliminating the need to run the entire scraper.
To initiate the Scrapy shell, execute:
For an enhanced shell experience with features like auto-completion and colored output, you can opt for IPython like this :
Then, configure your scrapy.cfg file to use IPython:
When you have the Scrapy shell, you'll be greeted with an interface resembling this for playing with your page :
In [7]: response.css('ul.pager').get()
Out[7]: '<ul class="pager">\n \n \n <li class="next">\n <a href="/page/2/">Next <span aria-hidden="true">→</span></a>\n </li>\n \n </ul>'
In [8]: response.css('ul.pager a').get()
Out[8]: '<a href="/page/2/">Next <span aria-hidden="true">→</span></a>'
In [9]: response.css('ul.pager a::text').get()
Out[9]: 'Next '
In [10]: response.css('ul.pager a::attr(href)').get()
Out[10]: '/page/2/'
Play with selectors
The first thing we want to do is fetch the main products page of the chocolate site in our Scrapy shell.
The you can see the return, Scrapy shell has automatically saved the HTML response in the response variable like this :
In [1]: fetch('http://quotes.toscrape.com')
2023-12-10 11:42:51 [scrapy.core.engine] INFO: Spider opened
In [2]: response
Out[2]: <200 http://quotes.toscrape.com>
Find quote CSS Selectors
To find the correct CSS selectors to parse our quote details we will first open the page in our browsers DevTools and inspect it with the dev tool, if you are not familiar with it it is very simple, you can check this quick tuto
Using the inspect element, hover over the item and look at the id's and classes on the individual quote. In this case we can see that each book has its own special component which is called <div class="col-md-8">. We can just use this to reference our quotes (see the image below).
You can notice also that the <div class="col-md-8"> is not exactly the <div> we want, we want the <div class="quote"> inside, let's practice a little with the scrapy shell.
Now using our Scrapy shell we can see if we can extract the quote informaton using this command here :
In [2]: response.css('div.col-md-8 div.quote')
Out[2]:
[<Selector query="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' col-md-8 ')]/descendant-or-self::*/div[@class and contains(concat(' ', normalize-space(@class), ' '), ' quote ')]" data='<div class="quote" itemscope itemtype...'>,
<Selector query="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' col-md-8 ')]/descendant-or-self::*/div[@class and contains(concat(' ', normalize-space(@class), ' '), ' quote ')]" data='<div class="quote" itemscope itemtype...'>,
<Selector query="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' col-md-8 ')]/descendant-or-self::*/div[@class and contains(concat(' ', normalize-space(@class), ' '), ' quote ')]" data='<div class="quote" itemscope itemtype...'>,
...
]
Great we have all the <div> element containing our quotes now let's get one with the get() function here :
In [5]: response.css('div.col-md-8 div.quote').get()
Out[5]: '<div class="quote" itemscope itemtype="http://schema.org/CreativeWork">\n <span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>\n <span>by <small class="author" itemprop="author">Albert Einstein</small>\n <a href="/author/Albert-Einstein">(about)</a>\n </span>\n <div class="tags">\n Tags:\n <meta class="keywords" itemprop="keywords" content="change,deep-thoughts,thinking,world"> \n \n <a class="tag" href="/tag/change/page/1/">change</a>\n \n <a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>\n \n <a class="tag" href="/tag/thinking/page/1/">thinking</a>\n \n <a class="tag" href="/tag/world/page/1/">world</a>\n \n </div>\n </div>'
Now that we have found the DOM node that contains our quote items, we will get all of them and save this data into a response variable and loop through the items and extract the data we need.
So can do this with the following command :
That's verify all our quote in the webpage are well detected like we want, now let's get them all 😻
In [7]: response.css('div.col-md-8 div.quote').getall()
Out[7]:
['<div class="quote" itemscope itemtype="http://schema.org/CreativeWork">\n <span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>\n <span>by <small class="author" itemprop="author">Albert Einstein</small>\n <a href="/author/Albert-Einstein">(about)</a>\n </span>\n <div class="tags">\n Tags:\n <meta class="keywords" itemprop="keywords" content="change,deep-thoughts,thinking,world"> \n \n <a class="tag" href="/tag/change/page/1/">change</a>\n \n <a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>\n \n <a class="tag" href="/tag/thinking/page/1/">thinking</a>\n \n <a class="tag" href="/tag/world/page/1/">world</a>\n \n </div>\n </div>',
'<div class="quote" itemscope itemtype="http://schema.org/CreativeWork">\n <span class="text" itemprop="text">“It is our choices, Harry, that show what we truly are, far more than our abilities.”</span>\n <span>by <small class="author" itemprop="author">J.K. Rowling</small>\n <a href="/author/J-K-Rowling">(about)</a>\n </span>\n <div class="tags">\n Tags:\n <meta class="keywords" itemprop="keywords" content="abilities,choices"> \n \n <a class="tag" href="/tag/abilities/page/1/">abilities</a>\n \n <a class="tag" href="/tag/choices/page/1/">choices</a>\n \n </div>\n </div>',
...
]
Now you have all the informations inside the <div>
Extract quotes details
Now lets extract the quote, author and tags of each quote from the list of quotes.
When we update our spider code, we will loop through the list of quotes with the getall() function. However, to find the correct selectors we will test the CSS selectors on the first element of the list q[0].
In [9]: q = response.css('div.col-md-8 div.quote')
In [10]: q[0]
Out[10]: '<div class="quote" itemscope itemtype="http://schema.org/CreativeWork">\n <span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>\n <span>by <small class="author" itemprop="author">Albert Einstein</small>\n <a href="/author/Albert-Einstein">(about)</a>\n </span>\n <div class="tags">\n Tags:\n <meta class="keywords" itemprop="keywords" content="change,deep-thoughts,thinking,world"> \n \n <a class="tag" href="/tag/change/page/1/">change</a>\n \n <a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>\n \n <a class="tag" href="/tag/thinking/page/1/">thinking</a>\n \n <a class="tag" href="/tag/world/page/1/">world</a>\n \n </div>\n </div>'
You can see that we have a <span> tag inside our divs, lets explore this :
In [13]: q[0].css('span')
Out[13]:
[<Selector query='descendant-or-self::span' data='<span class="text" itemprop="text">“T...'>,
<Selector query='descendant-or-self::span' data='<span>by <small class="author" itempr...'>]
You can simple select one of the following tag like this :
In [14]: q[0].css('span.text')
Out[14]: [<Selector query="descendant-or-self::span[@class and contains(concat(' ', normalize-space(@class), ' '), ' text ')]" data='<span class="text" itemprop="text">“T...'>]
If you want only the text just type :
you will have only the text part extracted from the html code, isn't wonderfull 🥳Now let's extract the link about the authors inside our quotes. For this y9ou can easly notice that our information is hiding inside <a> tags. With the same logic we can write :
In [19]: q[0].css('span a')
Out[19]: [<Selector query='descendant-or-self::span/descendant-or-self::*/a' data='<a href="/author/Albert-Einstein">(ab...'>]
href tag, let's extract it like this :
Code our spider
Now, that we've found the correct CSS selectors let's update our spider. Exit Scrapy shell with the exit() command or just Ctrl+D like most of the shells.
Our updated Spider code should look like this:
class QuoteSpider(scrapy.Spider):
name = 'quotespider'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
quote = response.css('div.col-md-8 div.quote')
for q in quote:
yield{
'quote' :q.css('span.text::text').get()
'author' : q.css('small::text').get()
'about' : 'http://quotes.toscrape.com'+q.css('span a').attrib['href']
'tags' : {tmp: None for tmp in q.css('div.tags a.tag::text').getall()}
}
Here, our spider does the following steps:
- Makes a request to 'https://quotes.toscrape.com/'.
- When it gets a response, it extracts all the quotes from the page using
quote = response.css('div.col-md-8 div.quote') - Loops through each quote, and extracts the infos using the CSS selectors we created.
- Yields(returns) these items so they can be output to the terminal and/or stored in a CSV, JSON, DB, etc.
Then you can run you script with this command :
You can also run the script and put the informations inside a json file like this :
quote.json file created inside your project directory, nice or whaat 🧙🏼♂️
Navigating to the "Next Page"
Up to this point, the code functions well, yet it only scrapes quotes from the first page of the our website, based on the URL specified in the start_url variable. But you might notice that our website have more pages 😂
The next reasonable action is to navigate to the subsequent page, if available, and extract item data from there as well. Let's explore how to accomplish this.
First, we should revisit our Scrapy shell, retrieve the page again, and determine the appropriate selector to identify the next page button. Same routine, fetch the page and inspect the sections of interest : inside the <nav> tag you will see a <ul class=pager>
Update your spider with the page handling, be carful inside this you have also the previous button not only the next, you can see this tutorial and adapt it for our case 🤓
class QuoteSpider(scrapy.Spider):
name = 'quotespider'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
quote = response.css('div.col-md-8 div.quote')
for q in quote:
yield{
'quote' :q.css('span.text::text').get()
'author' : q.css('small::text').get()
'about' : 'http://quotes.toscrape.com'+q.css('span a').attrib['href']
'tags' : {tmp: None for tmp in q.css('div.tags a.tag::text').getall()}
}
#code here
#next_page =
Use Items
Like we said in the begining of this tutorial items give you a way to structures your data and gives it a clear schema. Let's code this for our project here :
import scrapy
class QuotescrapItem(scrapy.Item):
# define the fields for your item here like:
quote = scrapy.Field()
author = scrapy.Field()
about = scrapy.Field()
tags = scrapy.Field()
Then we can add it into our custom spider like this :
class QuoteSpider(scrapy.Spider):
name = 'quotespider'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
quote = response.css('div.col-md-8 div.quote')
quote_item = QuotescrapItem()
for q in quote:
quote_item['quote'] = q.css('span.text::text').get()
quote_item['author'] = q.css('small::text').get()
quote_item['about'] = 'http://quotes.toscrape.com'+q.css('span a').attrib['href']
quote_item['tags'] = {tmp: None for tmp in q.css('div.tags a.tag::text').getall()}
yield quote_item
#handle next page
You can note that it is not very different from our previous code, the general structure is not changing much 🤓
Now that we have this, our next goal is to insert all our record inside some database, for this we have to do two main things :
- Write a little code inside the our
pipelines.pyfile - Add it into
settings.pyfile in order to appy it when we run our crawler
Insert scraped data into databases
We have seen earlier that we can save our scraped data into some json or csv file with the scrapy CLI like this :
or
You have two options when using this command, use are small -o or use a capital -O.
-o: appends new data to an existing file.-O: overwrites any existing file with the same name with the current data.
But it is much more efficient and reliable to store our scraped data inside some databases ! We will use docker to quickly instantiate our databases and we will go with MongoDB and Postgres for our little example.
MongoDB
You can find all the instruction to set up and connect to a MongoDB docker container in the Selenium section of this course. Let's assume from here that you have a proper MongoDB container up and running on your local machine.
First you will need to install the MongoDB python connector if it's not already on your environement. Then we need to edit our pipelines.py file and set up our mini pipeline.
First, we're going to import MongoClient into our pipelines.py file, and create an __init__ method that we will use to create our database and table named quote_database like this :
# pipelines.py
import mysql.connector
class SaveToMySQLPipeline:
def __init__(self):
pass
def process_item(self, item, spider):
return item
The __init__ method will configure the pipeline to do the following everytime the pipeline gets activated by a spider:
- Try to connect to our database
quote_databaseand if it doesn't exist create this new database - Create a cursor which we will use to execute mongo commands in the database
- Create a new collection named
quote_collectionwith all ourItemobject - Close the connection to not push your memory
#pipelines.py
from pymongo import MongoClient
class SaveToMongoPipeline:
def __init__(self):
#connect to the MongoDB server (default is localhost on port 27017)
self.conn = MongoClient('0.0.0.0', 27017)
#access the database (create it if it doesn't exist)
self.db = self.conn['quote_database']
#access the collection (similar to a table in relational databases)
self.collection = self.db['quote_collection']
def process_item(self, item, spider):
#dump item into MongoDB
pass
def close_spider(self, spider):
#close the connection to the database
self.conn.close()
Save scraped Items into Mongo
Next, we're going to use the process_item function inside in our pipeline to dump our data into our Mongo database very quickly like this :
def process_item(self, item, spider):
# Convert item to dict and insert into MongoDB
self.collection.insert_one(ItemAdapter(item).asdict())
return item
Run our pipeline
In order to run our pipeline we need to include it in our settings.py file here :
ITEM_PIPELINES = {
"quotescrap.pipelines.QuotescrapPipeline": 300, #other example cleaning function
"quotescrap.pipelines.SaveToMongoPipeline": 400, #number = priority event
}
Now, when we run our quotespider it will save the scraped data into our database 🥳
Access MongoDB CLI
First, you need to find the container ID or name of your MongoDB container. You can do this by listing all running Docker containers:
Look for the container running MongoDB and note down itsCONTAINER ID or NAME. Then, access the MongoDB CLI within the container using:
Replace
List all databases:
Switch to your specific database:
List all collections in your database:
Query data from your collection:
This command will display the contents of the quote_collection in a formatted way like this :
[
{
_id: ObjectId("6574c09fb48252134cbf1c23"),
quote: '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
author: 'albert einstein',
about: 'http://quotes.toscrape.com/author/Albert-Einstein',
tags: {
change: null,
'deep-thoughts': null,
thinking: null,
world: null
}
},
...
]
Postgres
You can do the same pattern with an other database like PostgreSQL easily like this :
import psycopg2
import json
class SavePostgreSQLPipeline:
def __init__(self):
# Connect to the PostgreSQL server
# Update the connection details as per your PostgreSQL configuration
self.conn = psycopg2.connect(
host='0.0.0.0',
dbname='postgres',
user='postgres',
password='fred'
)
self.cur = self.conn.cursor()
# Create table if it doesn't exist
self.cur.execute("""
CREATE TABLE IF NOT EXISTS quotes (
id SERIAL PRIMARY KEY,
quote TEXT,
author TEXT,
about TEXT,
tags JSONB
)
""")
self.conn.commit()
def process_item(self, item, spider):
# Convert item to dict
item_dict = ItemAdapter(item).asdict()
# Insert data into the table
self.cur.execute("""
INSERT INTO quotes (quote, author, about, tags) VALUES (%s, %s, %s, %s)
""", (item_dict['quote'], item_dict['author'], item_dict['about'], json.dumps(item_dict['tags'])))
self.conn.commit()
return item
def close_spider(self, spider):
# Close the cursor and connection to the database
self.cur.close()
self.conn.close()
then eddit the settings.py file in order to add our new step :
#cleaning + save into mongo & postgres
ITEM_PIPELINES = {
"quotescrap.pipelines.QuotescrapPipeline": 300,
"quotescrap.pipelines.SaveToMongoPipeline": 400,
"quotescrap.pipelines.SavePostgreSQLPipeline": 401,#after saving to mongo
}
You can do the same things for verification 🤓
Scaling
Add user agent to our scrapy request
Another option is to set a user-agent on every request your spider makes by defining a user-agent in the headers of your request like this :
## YourCustomSpider.py
def start_requests(self):
for url in self.start_urls:
return scrapy.Request(url=url, callback=self.parse,
headers={"User-Agent": "Mozilla/5.0 (iPad; CPU OS 12_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148"})
def start_requests(self):
user_agent_list = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
'Mozilla/5.0 (iPhone; CPU iPhone OS 14_4_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Mobile/15E148 Safari/604.1',
'Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1)',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363',
]
fake_browser_header = {
"upgrade-insecure-requests": "1",
"user-agent": "",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"sec-ch-ua": "\".Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"103\", \"Chromium\";v=\"103\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Linux\"",
"sec-fetch-site": "none",
"sec-fetch-mod": "",
"sec-fetch-user": "?1",
"accept-encoding": "gzip, deflate, br",
"accept-language": "fr-CH,fr;q=0.9,en-US;q=0.8,en;q=0.7"
}
for url in self.start_urls:
userr = user_agent_list[randint(0, len(user_agent_list)-1)]
fake_browser_header["user-agent"] = userr
print(f"\n************ New User Agent *************\n{userr}\n")
yield scrapy.Request(url=url, callback=self.parse, headers=fake_browser_header)
You can use generative AI like ChatGPT for generating fake headers and user agent or use a proper tool to do it like The ScrapeOps Fake Browser Header API is a freenium fake browser header API, that returns a list of fake browser headers.
To use it you just need to send a request to their API endpoint to retrieve a list of user-agents but you first need an API key which you can get by signing up for a free account.
The best way to integrate the Fake Browser Headers API is to create a Downloader middleware and have a fake browser headers be added to every request but we will not go into this kind of details here. But the idea is pretty much the same : edit the middlewares.py file according to your need then save the congig inside your settings.py file like this:
#settings.py
SCRAPEOPS_API_KEY = 'YOUR_API_KEY'
SCRAPEOPS_FAKE_BROWSER_HEADER_ENABLED = True
DOWNLOADER_MIDDLEWARES = {
'bookscraper.middlewares.ScrapeOpsFakeBrowserHeaderAgentMiddleware': 400,
}
Same for proxies rotating, based on the same idea you can use different IP address for each requests. You can find more about proxies and hearders in the Selenium section. Keep this into your head, we will use it later for better scaling and monitoring our crawler 🤖
Manage thousands of fake user agents with ScrapeOps
To take a closer look to user agent concept go to the Selenium section of this course, you will find there more details about headers and how we can handle it in python 😎
For more scalable solution I recommend you this super tutorial on how to manage thousands of fake user agents here
Deploy and schedule jobs with Scrapyd
Now that we have set up our crawler, our database and some spicy techniques to scrap like a spy it will be cool if we can run it in the cloud and manage jobs. You can find all about scrapyd throught the official doc
To run jobs using Scrapyd, we first need to eggify and deploy our Scrapy project to the Scrapyd server. To do this, there is a library called scrapyd-client that makes this process very simple. First, let's install scrapyd-client:
Once installed, navigate to our bookscraper project we want to deploy and open our scrapyd.cfg file, which should be located in your project's root directory.
You should see something like this :
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html
[settings]
default = quotescrap.settings
shell = ipython
[deploy]
url = http://localhost:6800/
project = quotescrap
Then run the following command in your Scrapy projects root directory:
This will then eggify your Scrapy project and deploy it to your locally running Scrapyd server. You should get a result like this in your terminal if it was successful:
Packing version 1702212619
Deploying to project "quotescrap" in http://localhost:6800/addversion.json
Server response (200):
{"node_name": "benjamin.local", "status": "ok", "project": "quotescrap", "version": "1702212619", "spiders": 1}
6800 port of your local machine and run a job like the doc said you will see something like this :
and see your job in the job section :
You can also set up a scrapydcluster on Heroku with this super github here and deploy and run distributed spiders with GUI like this :
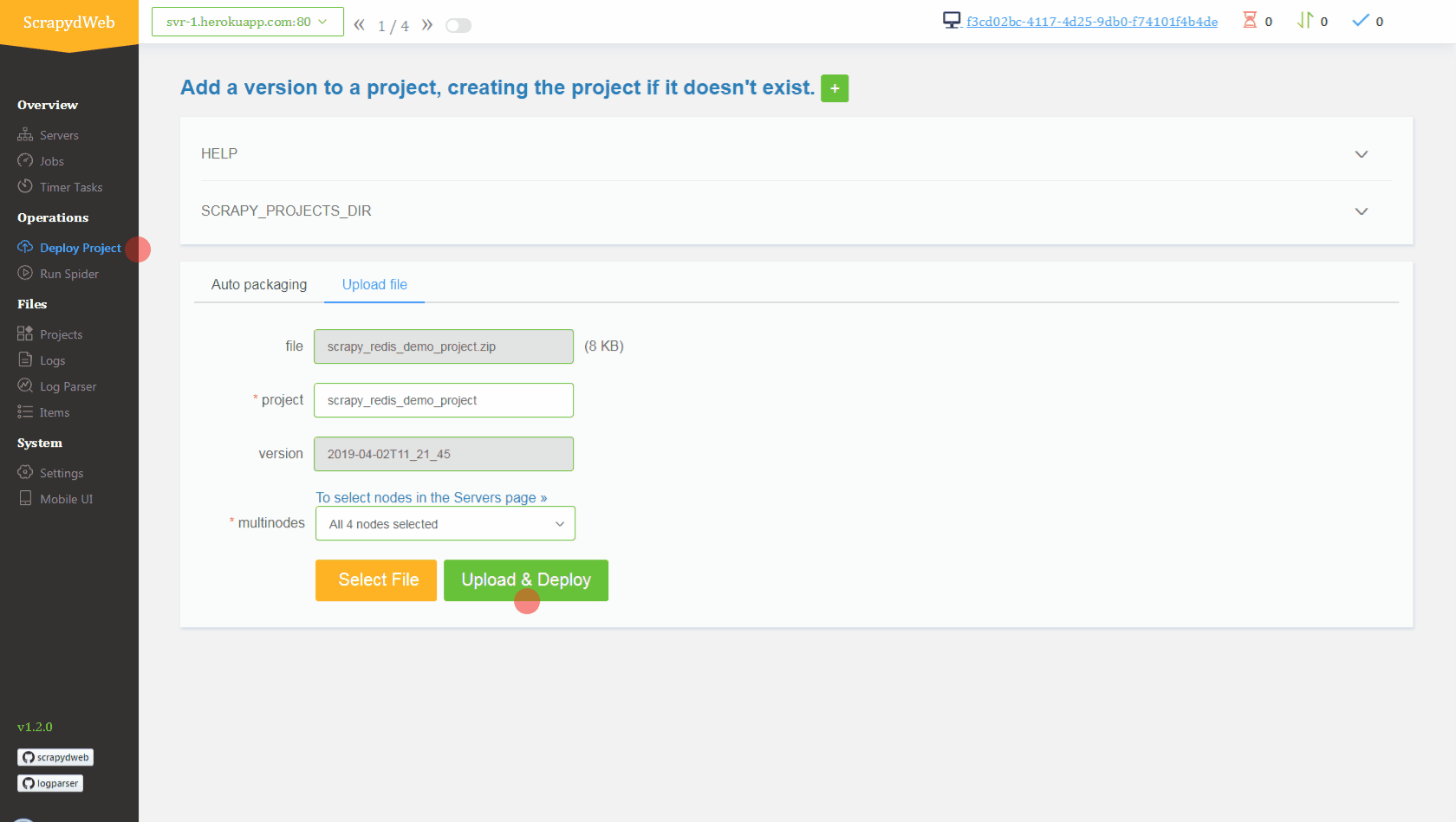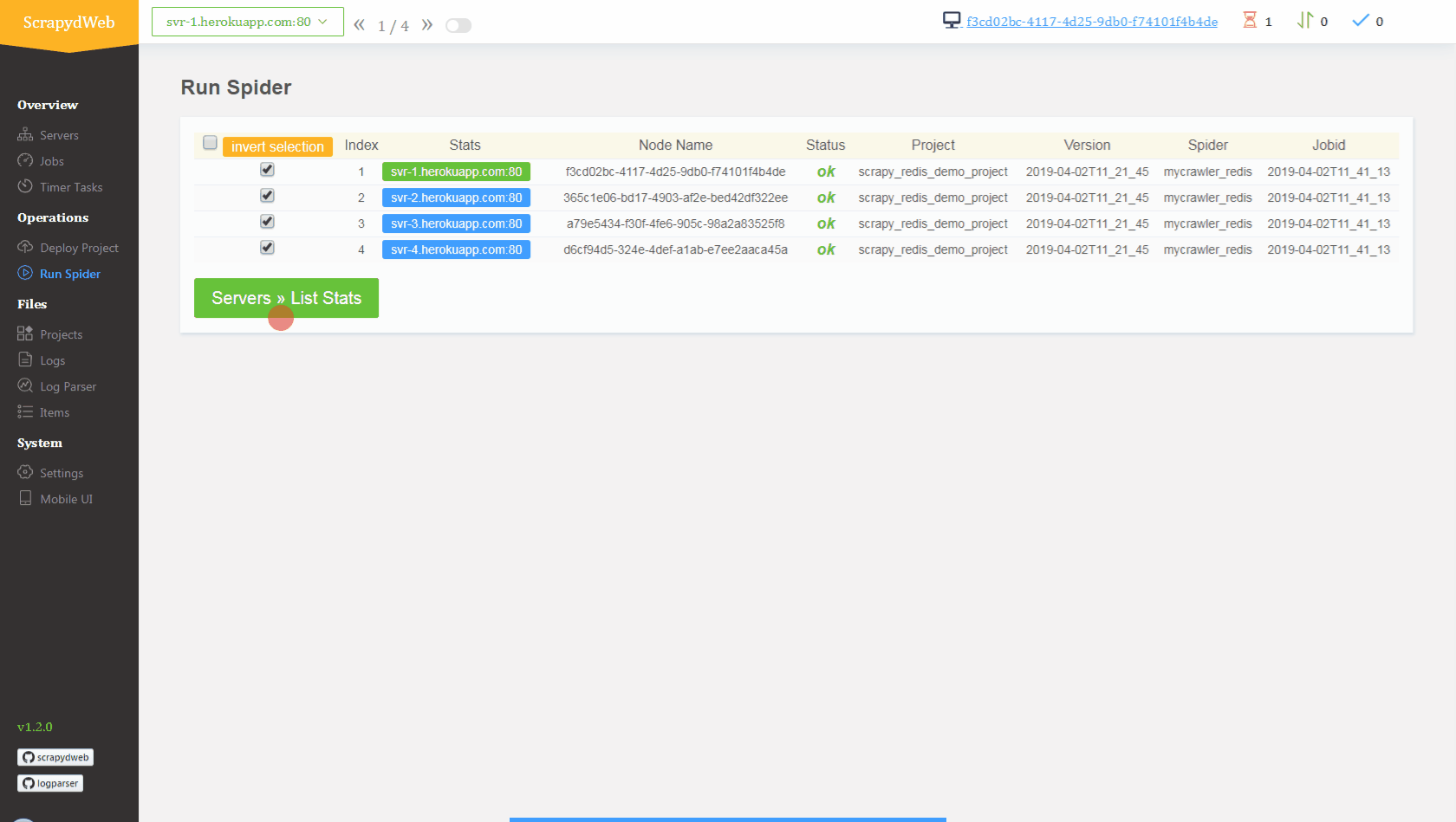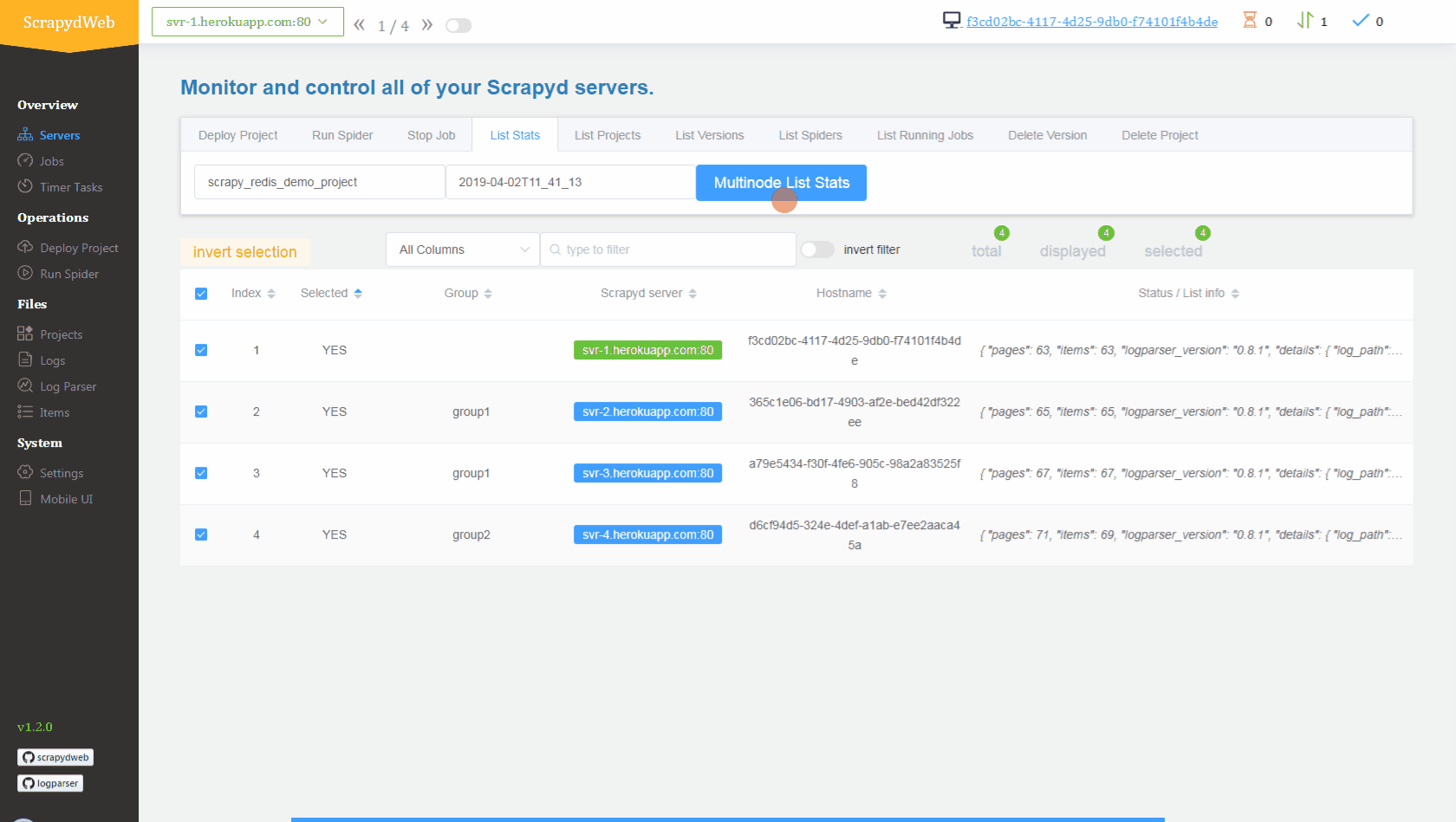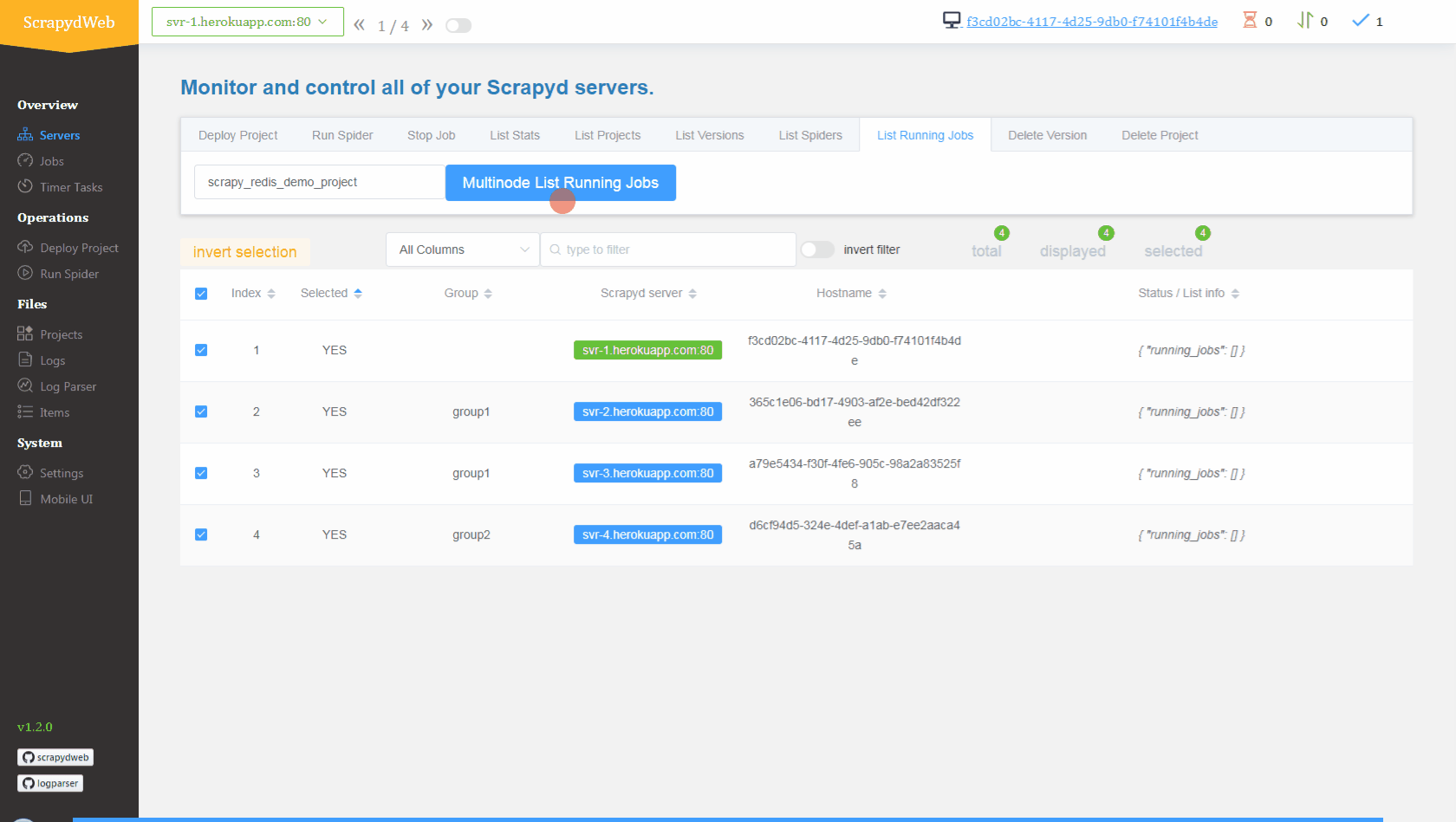
Congrat's you now have set up your first job in a separate server 🥳
Monitoring
Follow this tutorial here in order to install the scrapeops SDK and synchronize your script then lunch a job you will see on the dashboard the following spider like this :
You can also enjoy the nice scrapeops GUI features like schedule a job see some KPIs 😎