Scraping data with python¶
According to Wikipedia Web scraping is data scraping used for extracting data from websites. Web scraping software may directly access the World Wide Web using the Hypertext Transfer Protocol or a web browser. While web scraping can be done manually by a software user, the term typically refers to automated processes implemented using a bot or web crawler. It is a form of copying in which specific data is gathered and copied from the web, typically into a central local database or spreadsheet, for later retrieval or analysis.
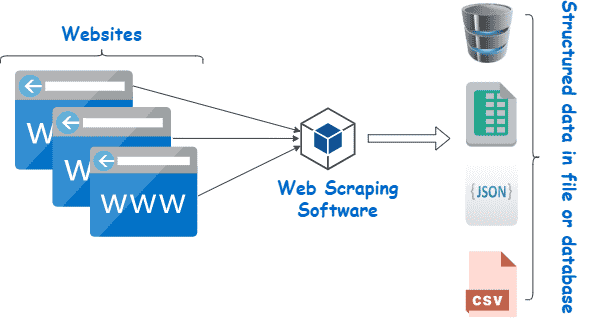
Goals 🚀¶
In order to be a real scraping ninja we will learn in this course :
- What is scraping and how DOM web data are organised
- What is an HTTP request and handle them with python
- What is concurrency, parallelism, threading and multiprocessing programming
- Leverage asynchronous programming in python
- Leverage proxies and headers rotating
- Handle the principal python libraries for scraping : BeautifulSoup, Selenium and Scrapy
Let's begin with understanding simple requests with the requests library of python.
Making requests¶
import requests
import pandas as pd
# simple request on webpage
page = requests.get("http://dataquestio.github.io/web-scraping-pages/simple.html")
page
<Response [200]>
print(page.content)
b'<!DOCTYPE html>\n<html>\n <head>\n <title>A simple example page</title>\n </head>\n <body>\n <p>Here is some simple content for this page.</p>\n </body>\n</html>'
#formating
page.text.split("\n")
['<!DOCTYPE html>', '<html>', ' <head>', ' <title>A simple example page</title>', ' </head>', ' <body>', ' <p>Here is some simple content for this page.</p>', ' </body>', '</html>']
As you may saw it is not the perfect return format... We will see how to leverage the tags and extract the text directly. For this we'll be using beautifulsoup library, an indispensable parser and tag browser for larger pages.
First let's view how to handle data with python if you are not familiar with this langage.
Data wrangling overview¶
Data wrangling, also known as data munging or data handling, is a crucial step in the data preparation process, and it plays a significant role in web scraping. In order to master web scraping you will have to :
- Cleaning and structuring Raw Data
- Data Transformation : aggregation and summarization
- Integration with other Data sources
- Preparing for analysis and visualization
First thing thirst, let's see how to manage basics files like json, csv, txt, and xml files.
Manage static files in python¶
Knowing how to manage files in Python is crucial before diving deeper into web scraping for saving scraped data in various formats. Without the ability to efficiently write to and read from files, it would be challenging to handle the data collected via scraping.
Let's begin by reading and writing in a txtfile here :
# Attempt to read from a file
try:
with open('example.txt', 'r') as file:
content = file.read()
print(content)
except FileNotFoundError:
# If the file does not exist, create it and write a default message
with open('example.txt', 'w') as file:
file.write("This is a new file.")
print("File 'example.txt' was not found and has been created.")
This is a new file.
with open('example.txt', 'r') as file:
content = file.read()
print(content)
This is a new file.
We can also use the native os library in order to navigate into our file system like this :
import os
#list all files in a directory
for file in os.listdir('/Users/mac/workspace/ds_course/micro-services/jenkins'):
print(file)
.DS_Store app .env Jenkinsfile docker-compose.yml
with open('example.txt', 'r', encoding='utf-8') as file:
content = file.read()
print(content)
This is a new file.
Reading and writing json¶
import json
data = [
{
"name": "Alice Brown",
"department": "Marketing",
"salary": 70000
},
{
"name": "Bob Smith",
"department": "Sales",
"salary": 65000
},
{
"name": "Carol Jones",
"department": "IT",
"salary": 75000
}
]
#write this variable inside a json file
with open('output.json', 'w') as file:
json.dump(data, file, indent=4)
#then read the data
with open('output.json', 'r') as file:
data = json.load(file)
print(data)
[{'name': 'Alice Brown', 'department': 'Marketing', 'salary': 70000}, {'name': 'Bob Smith', 'department': 'Sales', 'salary': 65000}, {'name': 'Carol Jones', 'department': 'IT', 'salary': 75000}]
Generator¶
Generators are a type of iterable, like lists or tuples, but they generate items on-the-fly and don't store them in memory. This makes them more memory-efficient for large datasets. We use the yield keyword in order to call them.
The efficiency of the generator approach is noticeable if the file is large, as it processes one line at a time without loading the entire file into memory. The traditional approach may be slower due to the overhead of loading the entire file, let's see that !
import time
import requests
import csv
from io import StringIO
%time
def csv_reader(file_content):
return csv.reader(StringIO(file_content))
# Fetch the file content from the URL
url = 'https://gist.githubusercontent.com/bdallard/d4a3e247e8a739a329fd518c0860f8a8/raw/82fb43adc5ce022797a5df21eb06dd8e755145ea/data-json.csv'
response = requests.get(url)
file_content = response.text
tmp=0
start_time = time.time()
csv_data = csv_reader(file_content)
for row in csv_data:
tmp+=int(row[0][-1]) #some dummy operation
end_time = time.time()
print("Traditional approach took:", end_time - start_time, "seconds")
CPU times: user 2 µs, sys: 0 ns, total: 2 µs Wall time: 5.25 µs Traditional approach took: 0.03126811981201172 seconds
%time
def csv_reader_gen(file_content):
for row in csv.reader(StringIO(file_content)):
yield row
# Fetch the file content from the URL
url = "https://gist.githubusercontent.com/bdallard/d4a3e247e8a739a329fd518c0860f8a8/raw/82fb43adc5ce022797a5df21eb06dd8e755145ea/data-json.csv"
response = requests.get(url)
file_content = response.text
tmp=0
start_time = time.time()
csv_gen = csv_reader_gen(file_content)
for row in csv_gen:
tmp+=int(row[0][-1]) #some dummy operation
end_time = time.time()
print("Generator approach took:", end_time - start_time, "seconds")
CPU times: user 2 µs, sys: 0 ns, total: 2 µs Wall time: 5.01 µs Generator approach took: 0.04893088340759277 seconds
HTTP in a nutshell¶
HTTP stands for HyperText Transfer Protocol. It's the foundation of data communication on the World Wide Web. Essentially, it's a protocol used for transmitting data over a network. Most of the information that you receive through your web browser is delivered via HTTP.
An HTTP request is a message sent by a client (like a web browser or a mobile app) to a server to request a specific action. This action can be fetching a web page, submitting form data, downloading a file, etc.
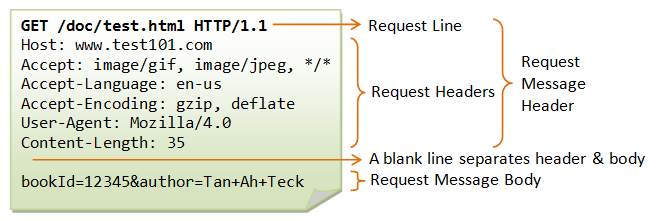
As you can see on the schema above an HTTP request is formed with :
- Method: Indicates what type of action you're requesting. Common methods include GET (retrieve data), POST (submit data), PUT (update data), and DELETE (remove data).
- URL (Uniform Resource Locator): Specifies the location of the resource (like a web page or an image) on the server.
- Headers: Provide additional information (like the type of browser making the request, types of response formats that are acceptable, etc.).
- Body: Contains data sent to the server. This is typically used with POST and PUT requests.
How does it work ?
When you type a URL into your browser and press Enter, your browser sends an HTTP GET request to the server that hosts that URL. The server processes the request, and if everything goes well, it sends back a response. This response usually contains the HTML content of the web page you requested.
The response from the server includes a status code (like 200 for a successful request, 404 for not found, etc.), headers (similar to request headers but providing information from the server), and usually, a body (which contains the requested data, if any). See http codes on wikipedia.
HTTP is a stateless protocol, meaning each request-response pair is independent. Servers don't retain information about previous interactions. Techniques like cookies are used to "remember" state across requests.
Secure HTTP - HTTPS¶
When security is a concern, HTTPS (HTTP Secure) is used. It encrypts the request and response, protecting the data from being read or tampered with by intermediaries. See more details about basic certificates into de docker https section.
Example with the request python module¶
response = requests.get('http://httpbin.org/ip')
#print(response.json()['origin']) #your personnal ip

#install free proxy tool from : https://github.com/jundymek/free-proxy
#!pip install free-proxy
You can also find free proxies here : https://free-proxy-list.net
Or more pro solutions for goods tool like Captia bypass here : https://www.zenrows.com/solutions/bypass-captcha
from fp.fp import FreeProxy
import requests
from bs4 import BeautifulSoup
proxy = FreeProxy(country_id=['FR']).get(); proxy
'http://103.127.1.130:80'
proxy_list = [FreeProxy(country_id=['FR']).get() for x in range(3)]; proxy_list
['http://139.59.1.14:8080', 'http://20.24.43.214:80', 'http://20.24.43.214:80']
proxies = {'http': proxy_list[1]}
response = requests.get('http://httpbin.org/ip', proxies=proxies)
print(response.json()['origin']) # our proxy !!
20.24.43.214
Great we have now a different IP address, at least the server detect an other ip and not our public router IP 🧙🏼♂️
Headers¶
Now let's get deeper a little with our request header in order to fool our target with User-Agent (abbreviated as UA). A user agent is a string that a web browser sends to a web server identifying itself. This string contains details about the browser type, rendering engine, operating system, and sometimes device type. In web scraping, the user agent plays a crucial role for several reasons:
- Browser Identification: The user agent tells the server what kind of browser is making the request. Different browsers may support different features or render web pages differently.
- Device and OS Identification: The user agent can also indicate the operating system and the device (desktop, mobile, tablet, etc.), which can affect how web content is delivered.
Let's see a basic example of the informations the target site will get if we use Python Requests or cURL without any modifications.
response = requests.get('http://httpbin.org/headers')
print(response.json()['headers'])
# python-requests/2.25.1
{'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.31.0', 'X-Amzn-Trace-Id': 'Root=1-65733af4-7e6abbd77660881e470ae532'}
!curl http://httpbin.org/headers
{
"headers": {
"Accept": "*/*",
"Host": "httpbin.org",
"User-Agent": "curl/7.64.1",
"X-Amzn-Trace-Id": "Root=1-65733af5-2f7996e30facb6690797b21e"
}
}
#try a custom user-agent
headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36"}
response = requests.get('http://httpbin.org/headers', headers=headers)
print(response.json()['headers']['User-Agent']) # Mozilla/5.0 ...
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36
#more user-agent, thanks chatgpt 🤓
import random
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
'Mozilla/5.0 (iPhone; CPU iPhone OS 12_2 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Mobile/15E148',
'Mozilla/5.0 (Linux; Android 11; SM-G960U) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.72 Mobile Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0',
'Mozilla/5.0 (iPad; CPU OS 13_5 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Mobile/15E148 Safari/604.1',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/604.1.34 (KHTML, like Gecko) Edge/90.0.818.56',
'Mozilla/5.0 (Linux; Android 10; SM-A505FN) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Mobile Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.3 Safari/605.1.15',
'Mozilla/5.0 (Linux; Android 11; Pixel 3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Mobile Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (iPhone; CPU iPhone OS 14_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Mobile/15E148 Safari/604.1',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:88.0) Gecko/20100101 Firefox/88.0'
]
user_agent = random.choice(user_agents)
headers = {'User-Agent': user_agent}
response = requests.get('https://httpbin.org/headers', headers=headers)
print(response.json()['headers']['User-Agent'])
# Mozilla/5.0 (iPhone; CPU iPhone OS 12_2 like Mac OS X) ...
Mozilla/5.0 (iPad; CPU OS 13_5 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.1 Mobile/15E148 Safari/604.1
If you take a closer look to our request here you will see the entier header look like this :
{
"headers": {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "fr-fr",
"Host": "httpbin.org",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.6.1 Safari/605.1.15",
"X-Amzn-Trace-Id": "Root=1-6572fed4-5a7b863b4842def83f9030c4"
}
}
headers_list = [
{
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9",
"Host": "httpbin.org",
"Sec-Ch-Ua": "\"Chromium\";v=\"92\", \" Not A;Brand\";v=\"99\", \"Google Chrome\";v=\"92\"",
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
},
{
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.5",
"Host": "httpbin.org",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:90.0) Gecko/20100101 Firefox/90.0"
},
{
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.5",
"Host": "httpbin.org",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 14_6 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Mobile/15E148 Safari/604.1"
},
{
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-GB,en;q=0.5",
"Host": "httpbin.org",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0"
},
{
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9",
"Host": "httpbin.org",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.1.2 Safari/605.1.15"
}
]
headers = random.choice(headers_list)
response = requests.get('https://httpbin.org/headers', headers=headers, proxies=proxies)
print(response.json()['headers'])
{'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'en-GB,en;q=0.5', 'Host': 'httpbin.org', 'Sec-Fetch-Dest': 'document', 'Sec-Fetch-Mode': 'navigate', 'Sec-Fetch-Site': 'none', 'Sec-Fetch-User': '?1', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0', 'X-Amzn-Trace-Id': 'Root=1-65733af9-0e45d0f96abddec2158e071e'}
Concurrency and parallelism¶

Concurrency¶
Concurrency is about dealing with multiple tasks at the same time. It doesn't necessarily mean these tasks are executed simultaneously. It's more about the structure of the program, where tasks are broken into smaller, independent units which are processed in overlapping time periods.
Concurrency use case¶
Web scraping involves fetching data from multiple web pages simultaneously. By employing concurrency, you can make concurrent requests to different web pages using threads or asynchronous programming libraries like asyncio or gevent. This allows for efficient utilization of I/O resources and faster data retrieval.
Parallelism¶
Parallelism in the contrary is about doing multiple tasks simultaneously, often requiring multiple processors or cores. It's about executing multiple operations at the exact same time.
Parallelism use case¶
When dealing with large datasets, parallelism can significantly enhance data processing speed. For instance, if you need to perform complex calculations on each data point independently, you can distribute the workload across multiple CPU cores using multiprocessing. Each core can handle a portion of the data, leading to faster overall processing time.
Threading and Multiprocessing¶
Threading¶
Threading in Python allows for concurrent execution of tasks by utilizing multiple threads within a single process. Threads share the same memory space and can switch rapidly between tasks, giving the illusion of parallel execution. However, due to the Global Interpreter Lock (GIL) in Python, threading is more suitable for I/O-bound tasks, where threads can wait for I/O operations without blocking the entire process. This makes threading well-suited for achieving concurrency in Python applications.
import threading
#define a function that must be executed using threads
def thread_function(name):
print("Hello from thread", name)
#create a thread and execute the function
thread = threading.Thread(target=thread_function, args=("Thread 1",)) #create a thread taking our desired function as arguement
thread.start()
thread.join() #thread.start() starts the thread and thread.join() stops the thread
Multiprocessing¶
Multiprocessing in Python enables true parallelism by utilizing multiple processes that can run on separate CPU cores. Each process has its own memory space, allowing for independent execution of tasks.
Multiprocessing is ideal for CPU-bound tasks, where the workload can be divided and executed in parallel across multiple cores. Unlike threading, multiprocessing can fully utilize multiple CPU cores and achieve significant speed improvements for parallel tasks.
import multiprocessing module
import multiprocessing
#define the function that must be executed parallely
def process_function(name):
print("Hello from process", name)
#start the process using multiprocessing.Process() method, it takes function name as arguement
process = multiprocessing.Process(target=process_function,args=("process1",))
process.start() #process.start() starts the process and process.join() stops the process
process.join()
More example on the geeksforgeeks website 🤖
Example in python¶
Let's code a little example and evaluate the time it takes to download some images using three different methods in Python: a standard approach, threading, and multiprocessing.
For this purpose, we'll employ the threading and multiprocessing modules to implement the respective methods, and the timeit module will be used for timing the processes.
Our objective is to highlight the performance variation among these techniques. By recording how long it takes to download several images with each technique, we'll be able to see how concurrency and parallelism affect the total time required for execution.
Because we are smart coders we will download very little images (1px,1px) from this site : https://picsum.photos/1 🤓
import timeit
import requests
import threading
import multiprocessing
image_urls = []
for i in range(0,100):
image_urls.append(f'https://picsum.photos/{i}')
len(image_urls)
100
def download_image(image_url):
response = requests.get(image_url)
if response.status_code == 200:
with open(f"images/{image_url.split('/')[-1]}.png", 'wb') as f:
f.write(response.content)
else:
print(f'Error downloading image {image_url}')
def normal_execution():
start = timeit.default_timer()
for image_url in image_urls:
download_image(image_url)
end = timeit.default_timer()
print(f'Normal Execution Time for {len(image_urls)} images: {end-start}')
normal_execution()
Normal Execution Time for 100 images: 26.95955391699954
def threading_download():
start = timeit.default_timer()
threads = []
for image_url in image_urls:
t = threading.Thread(target=download_image,args=(image_url,))
threads.append(t)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
end = timeit.default_timer()
print(f'Threading Execution Time for {len(image_urls)} images: {end-start}')
threading_download()
Threading Execution Time for 100 images: 13.221584853999957
def multiprocessing_download():
start = timeit.default_timer()
processes = []
for image_url in image_urls:
#print('downloading image ',image_url)
p = multiprocessing.Process(target=download_image,args=(image_url,))
processes.append(p)
for process in processes:
process.start()
for process in processes:
process.join()
end = timeit.default_timer()
print(f'Multiprocessing Execution Time for {len(image_urls)} images:: {end-start}')
multiprocessing_download()
Multiprocessing Execution Time for 100 images:: 4.486782826000308
Introduction to Asynchronous Programming¶
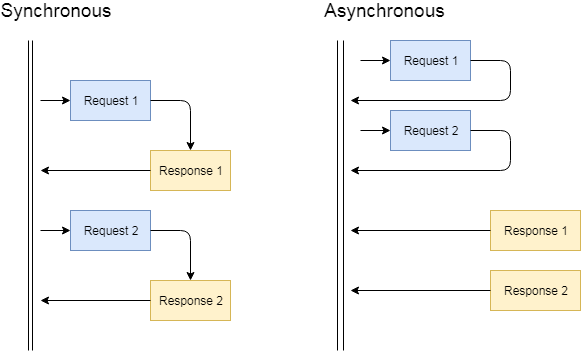
Asynchronous programming is a type of parallel programming in which a unit of work is allowed to run separately from the primary application thread. When the work is complete, it notifies the main thread about completion or failure of the worker thread.
There are numerous benefits to using it, such as improved application performance and enhanced responsiveness but we will not go into pythonic details here.
More informations :