Introduction to local knowledge graph
Mini lab - Building a local Knowledge Graph RAG with Neo4j, LangChain, and Ollama 🦙
In this lab we will be building a small knowledge graph from Wikipedia, loading it into Neo4j, and querying it with natural language using Langchain library and a local LLM (Ollama).
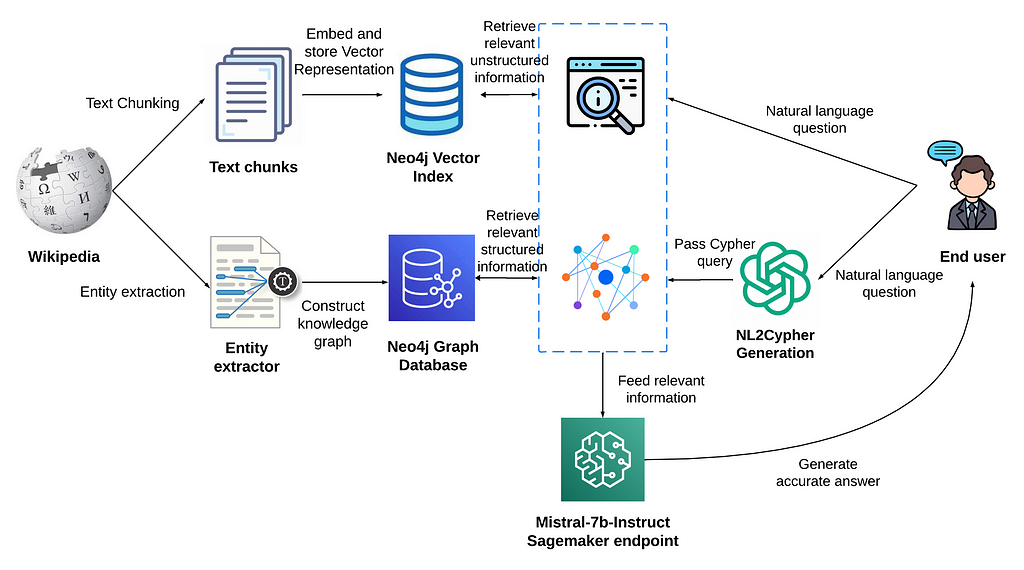
We will try to replicate the following architecture from the official neo4j blog with a local LLM through ollama app.
Learning goals 🎯
- use an external api
- extract entities and relationships from text into a knowledge graph
- load graph data into Neo4j and inspect it with Cypher
- play with Cypher and Langchain
👉 You will be uploading your results inside your personnal PUBLIC github repository, as usal this is a personnal project.
You can deliver this lab in a jupyter notebook format (and optionnal python scripts, but you will need to have a notebook at the root of you github repo to demonstrate your solution)
Prerequisites & setup
- Python 3.10+
- Neo4j available locally (via Docker)
- Ollama running locally with some model pulled (e.g.,
llama3:8b) - A FREE Diffbot API key for entity/relationship extraction (NO CB REQUIRED, ⚠️ do not put your cb ⚠️). You can set it as an environment variable
DIFFBOT_API_KEY, or edit the notebook cell that initializesDiffbotGraphTransformer.
1) Create and activate a virtual environment : 2) Install the given dependencies :
pip install -U langchain langchain-experimental langchain-openai langchain-neo4j neo4j wikipedia langchain-community langchain-text-splitters
services:
neo4j:
image: neo4j:5.20
environment:
NEO4J_AUTH: neo4j/password
NEO4J_PLUGINS: '["apoc","graph-data-science","bloom"]'
NEO4J_dbms_security_procedures_unrestricted: "apoc.*,gds.*"
NEO4J_server_config_strict__validation_enabled: "false"
NEO4J_dbms_default__database: shop
ports: ["7474:7474","7687:7687"]
volumes:
- ./neo4j/data:/data
- ./neo4j/import:/import
4) Start Ollama and pull a model:
Walkthrough
-
Ensure core packages are installed inside the notebook environment (be aware of dep conflict)
-
Load a Wikipedia articles with this lanchain module from some names or famous character and extract the documents with Diffbot api
You can choose any person or topic for example
WikipediaLoader(query="Satoshi Nakamoto") -
Connect to Neo4j and ingest the graph: clean the DB first it's not empty, and add the extracted graph documents from diffbot.
-
Then you can query relationships around Satoshi (or your topic/person)
Run a Cypher query to inspect relationships from
:Personnodes relating to “Satoshi Nakamoto” for example. -
Do some graph exploration and analysis : list node labels, inspect raw relationships, graph visualization
-
Write graph exploration queries (top connections, interests, employment, etc.)Run several Cypher snippets to explore the graph (e.g., most connected people, interests, employment, locations, competitors, founded-by).
-
Verify that the target entity exists and see how it’s represented (if multiple “Satoshi Nakamoto” nodes exist, how would you choose the "one"?)
-
Write a python reusable function to query all relationships for a person.
-
Create a
GraphCypherQAChainwith a custom Cypher prompt andChatOllamamodel.What elements in the custom prompt help the model generate correct Cypher for your schema?
-
Wrap the chain invocation to simplify later usage with a
ask_graph(question)helper function. -
Implement
get_entity_subgraphandsummarize_entityfunctions to build structured context and prompt an LLM for summaries.What information from the graph would you add/remove to improve the quality and factuality of summaries?
-
Question : Does the LLM hallucinate dates or facts? How would you constrain it to avoid this?
Some tips
- Dependency warnings: If you see
langchain-coreincompatibilities, align versions acrosslangchain,langchain-community,langchain-openai,langchain-neo4j,langchain-experimental, andlangchain-text-splitters. Pinning versions in arequirements.txtfile will help you 🥸 - Neo4j schema: If queries return empty, verify that labels and properties (
:Person,.id,.name) match the ones created by your extractor you can install the vscode plugin - Relationship unions: Prefer
MATCH (p)-[:EMPLOYEE_OR_MEMBER_OF|:WORK_RELATIONSHIP]->(o) - Ollama: ensure
ollama serveis running and your model is pulled. If responses are weak, try a larger model or adjust the prompt
Happy coding and remeber : RTFM 🤗