Introduction to Elasticsearch
Elasticsearch is an open-source, document-based NoSQL database that is designed for full-text search and analytics. Elasticsearch is built on top of the Lucene search engine and is optimized for fast search and retrieval of unstructured data.
Elastic architecture introduction
Elasticsearch is a distributed, document-oriented NoSQL database that is optimized for search and analytics. As we seen in the introduction part it is built on top of the Lucene search engine and is designed to scale horizontally across multiple nodes and clusters.
Cluster, nodes, shard and replicas
Nodes are individual instances of Elasticsearch that are part of a cluster. Each node stores a subset of the data in the cluster and is responsible for processing search and indexing requests for that data. Nodes can be added or removed from a cluster dynamically, allowing for easy scalability and fault tolerance.
Cluster
A cluster is a collection of one or more servers (known as nodes) that hold your entire data and provide federated indexing and search capabilities across all nodes.
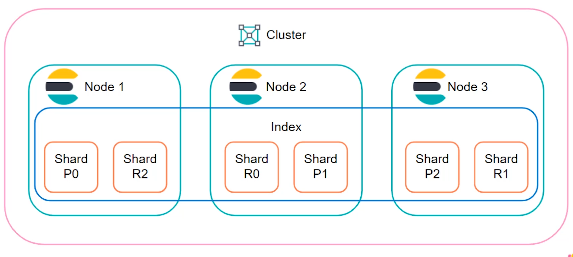
Elasticsearch clusters are designed to be highly available and fault tolerant, with built-in features for data replication and failover. Clusters can scale horizontally by adding more nodes to the cluster, allowing for increased processing power and storage capacity.
A cluster has several key characteristics:
- It is identified by a unique name, which by default is "elasticsearch".
- It allows you to add or remove nodes dynamically, without any downtime.
- It automatically routes requests to the appropriate nodes, whether it's an indexing request, a search request, or others.
- It automatically rebalances itself, which means it moves data from one node to another to ensure that all data is evenly distributed.
Prerequisites for installing an Elastic cluster
Before installing an Elasticsearch cluster, ensure the following prerequisites are met:
- Java: Elasticsearch is built using Java, and it requires Java to run. As of the date of writing, Elasticsearch requires at least Java 8. You can use either the OpenJDK or Oracle's JDK.
- Hardware: While the exact requirements depend on the size of your data and the nature of your tasks, generally, Elasticsearch benefits from having plenty of memory, ample CPU cores, and fast disk I/O. The official Elasticsearch guide recommends at least 64GB of RAM, and SSD drives are preferred over HDD for faster data retrieval.
- Operating System: Elasticsearch can run on several operating systems, including Linux, Windows, and macOS. However, it is commonly deployed on Linux.
- Network Settings: For a cluster to work correctly, all nodes should be able to communicate with each other. Ensure that your network settings and firewalls allow this communication.
Cluster configuration
The configuration of an Elasticsearch cluster involves setting up each node in the cluster and configuring the way they interact. Here are the steps to configure an Elasticsearch cluster:
Node Configuration
Each node's settings are located in the elasticsearch.yml configuration file in the config directory of the Elasticsearch installation. Key settings to consider include:
Node name: Each node must have a unique name within the cluster. Set the name with the node.name property.Cluster name: Each node must be set to join a named cluster. Set the cluster name with the cluster.name property.Node roles: By default, every node is a master-eligible and data node, meaning it can be elected as the master node and can store data. You can change the node type using the node.master and node.data settings.Network host and port: The network.host and http.port settings define the network address and port where the node will be accessible for communication with other nodes.
You can check at the full configuration file on the official github here You can notice that it is very long that's why we focused on few configurations parameters.
Discovery and Formation Settings
Cluster formation settings are crucial in a multi-node cluster to ensure nodes can discover each other and form a cluster:
Discovery seed hosts: The discovery.seed_hosts setting provides a list of host addresses for a new node to contact when trying to discover and join a cluster.Initial master nodes: The cluster.initial_master_nodes setting provides a list of the master-eligible nodes in the cluster to be contacted in order to form a new cluster.
Index Settings
You can also configure index settings, such as the number of primary shards and replica shards per index:
Number of shards: The index.number_of_shards setting defines the number of primary shards that an index should have.Number of replicas: The index.number_of_replicas setting defines the number of replicas each primary shard has.
Sharding and replication high overview
The number of shards and replicas can be configured for each index based on the size and search requirements of the data. For example, a large index with a high write throughput might require more primary shards to distribute the data more evenly across nodes, while a smaller index with a lower write throughput might require fewer primary shards to reduce the overhead of managing multiple shards.
Node types
As we have seen, a node refers to a running instance of Elasticsearch, which is a distributed search and analytics engine. Each node in an Elasticsearch cluster performs specific tasks and plays a crucial role in the overall functioning of the system. There are three main types of nodes in Elasticsearch:
Master Nodes: Master nodes are responsible for controlling the cluster, coordinating activities, and maintaining the cluster state. They handle tasks such as creating or deleting indices, managing metadata, and electing a new master node in case of failure. Having multiple master nodes ensures high availability and fault tolerance.Data Nodes: Data nodes store the actual data in an Elasticsearch cluster. They handle operations related to indexing, searching, and storing documents. Data nodes are responsible for shard allocation and data distribution across the cluster. By having multiple data nodes, you can achieve horizontal scalability and distribute the data workload across the cluster.Client Nodes: Client nodes serve as the interface between the client applications and the Elasticsearch cluster. They forward client requests to the appropriate nodes in the cluster and consolidate the responses. Client nodes help in load balancing and distributing search and indexing requests, providing a more efficient and scalable way to interact with the cluster.
By distributing the workload across multiple nodes, Elasticsearch can handle large amounts of data and high query loads and allows you to scale horizontally by adding more data nodes. We can also ensure Elastic clusters is resilient by having multiple master nodes to ensure that the cluster works even if one of the master nodes fails.
Finally, the ability to have different node types in an Elasticsearch cluster provides flexibility in resource allocation and optimization. You can allocate more resources to data nodes to handle heavy indexing or search operations, while dedicating specific nodes as master nodes or client nodes based on the cluster's needs.
Index
An index is like a database in a traditional relational database system. It is a logical container for one or more documents that share a similar structure and are stored together.
When you create an index in Elasticsearch, you can specify the mapping for the fields that the documents in the index will contain. The mapping defines the data types and formats for the fields, which allows Elasticsearch to index and search the data more efficiently.
You can also configure the number of primary shards that the index should have, which determines how the data in the index is distributed across nodes in the Elasticsearch cluster. This allows Elasticsearch to scale horizontally as the size of the index grows.
In addition, you can configure the number of replica shards for the index, which provide redundancy and allow for failover in case a primary shard becomes unavailable.
Overall, an index in Elasticsearch is a distributed, document-oriented NoSQL database that uses nodes, clusters, and sharding to provide scalability, fault tolerance, high availability and provides a way to organize and search data efficiently.
Overall architecture
The diagram shows a simplified architecture for an Elasticsearch cluster with three nodes. Each node is represented by a rectangular box and is labeled with its unique node name, IP address, and port number.
The nodes are connected to each other through a network, represented by the gray lines connecting the boxes. This network allows the nodes to communicate with each other and share data.
The Elasticsearch cluster is managed by a master node, which is responsible for coordinating the cluster and maintaining its state. In the diagram, the master node is indicated by the green box labeled "Master-eligible node."
The other nodes in the cluster are known as data nodes, and they are responsible for storing and indexing the data. In the diagram, the data nodes are indicated by the yellow boxes labeled "Data node."
Each data node stores a subset of the data in the cluster, and the data is distributed across the nodes using a technique called sharding. Each shard represents a portion of the data and is stored on a separate data node.
The client nodes, represented by the blue boxes labeled "Client node," are used to interact with the cluster and submit search and indexing requests. Client nodes do not store any data themselves, but they communicate with the data nodes to retrieve and manipulate the data.
Finally, the external world is represented by the orange box labeled "External clients," which can be any application or user that needs to interact with the Elasticsearch cluster.
Overall, the architecture diagram shows how an Elasticsearch cluster is composed of multiple nodes working together to store, index, and search data efficiently.
Installation Methods
Elasticsearch is a versatile tool that can be installed, configured, and used in numerous ways depending on the specific requirements and constraints of your system. Here is a detailed overview of various methods to install, configure, and use Elasticsearch.
- Install from Archive File: Elasticsearch is available as zip and tar.gz archive files for Windows and Linux/MacOS respectively. You can download the appropriate archive from the Elasticsearch website, extract it, and run the Elasticsearch binary directly.
- Install with Package Manager: On Linux systems, you can use a package manager like apt (for Debian-based distributions) or yum (for RPM-based distributions) to install Elasticsearch. This method is convenient as it takes care of installing Elasticsearch as a service, which automatically starts on system boot.
- Install with Docker: Elasticsearch is also available as a Docker image. This is an excellent option if you prefer containerization or if you want to ensure a consistent environment regardless of the host operating system. We will choose this option for the next part of this article.
- Use Elastic Cloud: If you don't want to manage your own Elasticsearch installation, you can use the Elastic Cloud, a hosted and managed Elasticsearch service provided by Elastic, the company behind Elasticsearch here
More about instllation options on the official documentation here
Installation with Docker
To install Elasticsearch, we can use Docker, a containerization platform that simplifies the process of installing and running software applications. Install Docker on your machine if you haven't already.
Open a command prompt and run the following command to download and run the Elasticsearch Docker image:
docker run -p 9200:9200 -p 9300:9300 -d -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.14.0
docker run: This command tells Docker to run a container from an image.-p9200:9200: This option maps port 9200 in the container to port 9200 on the host machine, allowing us to access Elasticsearch on port -9200from outside the container.-p9300:9300: This option maps port 9300 in the container to port 9300 on the host machine, allowing nodes in the Elasticsearch cluster to communicate with each other on port 9300.-d: This option runs the container in detached mode, which means it runs in the background and doesn't attach to the terminal. This allows us to continue using the terminal while the container is running.-e"discovery.type=single-node": This option sets an environment variable in the container called discovery.type to single-node. This tells Elasticsearch to start as a single-node cluster, which is useful for testing or development purposes.docker.elastic.co/elasticsearch/elasticsearch:7.14.0: This is the name and version of the Elasticsearch image we want to run.
When you run this command, Docker will download the Elasticsearch image from Docker Hub (unless it's already downloaded), create a container from the image, and start Elasticsearch running inside the container. The container will be accessible on port 9200 and 9300, and Elasticsearch will be running as a single-node cluster 🥳
For more information about docker installation you can check the official documention here
Test your installation
Cluster info
You can test if the elasticsearch container is running by run this command into your terminal (the jq command is here for a better return format, if you don't have it insall it here) :
You should see this :
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 390 100 390 0 0 308 0 0:00:01 0:00:01 --:--:-- 308
{
"cluster_name": "docker-cluster",
"status": "green",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 1,
"active_shards": 1,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}
This command returns information about the overall health of the Elasticsearch cluster. It provides information about the number of nodes in the cluster, the status of each node, the number of shards and replicas, and the overall status of the cluster. The response includes a variety of metrics such as the number of unassigned shards, the number of active and inactive primary shards, and the status of the cluster's overall health.
Nodes info
This command returns information about the nodes in the Elasticsearch cluster. It provides a summary of each node, including its IP address, node ID, and whether it is currently active or not. The response also includes a variety of metrics such as the number of open file descriptors, the amount of disk space used, and the amount of heap memory used.Set up a docker multi node architecture
Here's an example of a docker-compose.yml file that creates an Elasticsearch cluster with three nodes: a master node, a data node, and an ingest node :
version: '3'
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.15.0
container_name: es01
environment:
- node.name=es01
- node.roles=master
- cluster.name=es-docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- "discovery.seed_hosts=es02,es03"
- "cluster.initial_master_nodes=es01,es02,es03"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:7.15.0
container_name: es02
environment:
- node.name=es02
- node.roles=data
- cluster.name=es-docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- "discovery.seed_hosts=es01,es03"
- "cluster.initial_master_nodes=es01,es02,es03"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data02:/usr/share/elasticsearch/data
networks:
- elastic
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:7.15.0
container_name: es03
environment:
- node.name=es03
- node.roles=ingest
- cluster.name=es-docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- "discovery.seed_hosts=es01,es02"
- "cluster.initial_master_nodes=es01,es02,es03"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge
In this configuration, each service corresponds to an Elasticsearch node. Each node is configured with an environment variable node.roles which determines its role in the cluster: master, data, or ingest.
They all share the same cluster name es-docker-cluster, which is important for them to form a cluster. The discovery.seed_hosts and cluster.initial_master_nodes parameters are used for discovery and cluster formation.
The volumes section creates named Docker volumes for each node to persist Elasticsearch data across container restarts. To start the cluster, save the above configuration as docker-compose.yml and then run docker-compose up command.
Let's explore the pros and cons of having multiple node types within an Elasticsearch cluster.
Pros
- Specialized Roles: Different node types allow for specialized roles and optimized performance. Each node type can focus on its specific tasks, such as data storage, cluster coordination, or client request handling. This specialization enhances overall cluster efficiency and performance.
- Scalability: By incorporating multiple node types, you can scale your Elasticsearch cluster more effectively. Data nodes can be added to increase data storage and processing capacity, while additional client nodes can handle increased search and indexing traffic. This scalability enables your cluster to accommodate growing workloads and handle larger datasets.
- Fault Tolerance: Having multiple node types enhances fault tolerance within the cluster. With multiple master nodes, the cluster can maintain high availability and elect a new master node if one fails. Data nodes use shard replication to ensure data redundancy, reducing the risk of data loss in case of node failures. This fault tolerance improves the overall resilience of your Elasticsearch system.
- Load Distribution: Different node types allow for load distribution across the cluster. Client nodes can balance client requests, distributing the workload evenly among the available data nodes. This load distribution helps prevent bottlenecks and ensures efficient utilization of cluster resources.
Cons
- Increased Complexity: Introducing multiple node types adds complexity to the cluster configuration and management. You need to consider factors such as node roles, resource allocation, and communication between nodes. This complexity requires careful planning and monitoring to ensure proper cluster functioning.
- Resource Overhead: Each node type requires its own set of resources. Adding multiple node types may increase resource consumption, such as memory, CPU, and storage. If not managed properly, resource allocation can become inefficient, impacting overall performance and potentially increasing costs.
- Higher Maintenance Overhead: Managing a cluster with multiple node types can involve more administrative effort. Each node type may require specific configurations, monitoring, and maintenance tasks. For example, master nodes may need additional attention to ensure cluster stability and handle failover situations. This increased maintenance overhead should be taken into account when designing and operating the cluster. Setting up a complex docker multi node architecture is not recommanded.
- Network Communication: Communication and coordination between different node types require network bandwidth and can introduce additional latency. Depending on the cluster size and workload, network overhead may become a consideration. Proper network planning and optimization can help mitigate this potential drawback.
In summary, while having multiple node types in an Elasticsearch cluster offers benefits such as specialization, scalability, fault tolerance, and load distribution, it also introduces complexity, resource overhead, maintenance requirements, and potential network overhead. It is important to carefully assess your specific requirements and consider these pros and cons when deciding on the optimal node configuration for your Elasticsearch cluster.
Data Modeling in Elasticsearch
Elasticsearch stores data as JSON-like documents, which can be nested and hierarchical. The data model in Elasticsearch is flexible, allowing for easy changes to the schema.
Documents are the primary storage structure in Elasticsearch. Each document contains reserved fields (the document's metadata), such as:
_index: where the document resides_type: the type of document it represents (database)_id: a unique identifier for the document_source: the data in the form of a dictionary
json format overview
JSON (JavaScript Object Notation) is a lightweight data interchange format that is easy for humans to read and write and easy for machines to parse and generate. It consists of key-value pairs, with each pair separated by a comma and enclosed in curly braces. Here's an example of a simple JSON document:
In Elasticsearch, JSON is used as the primary format for documents that are stored and indexed in the database. Each document is represented as a JSON object, with fields that describe the properties of the document.Create an index and insert data
Remember, an index is like a database in a traditional relational database system.
We can create a specific index, let's say cities and give it a certain settings like 2 shards and 2 replicas per shards with the following command :
curl -XPUT 'http://localhost:9200/cities' -H 'Content-Type: application/json' -d '
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 2
}
}'
you should see this response :
To retrieve the index and verify its settings:
you should see this output :
{
"cities": {
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "2",
"provided_name": "cities",
"creation_date": "1678636556321",
"number_of_replicas": "2",
"uuid": "vsqBEmHWSBaki2AL-oClsA",
"version": {
"created": "7110199"
}
}
}
}
}
Now let's populate this index by creating our first document by running into our terminal :
curl -XPOST 'http://localhost:9200/cities/_doc' -H 'Content-Type: application/json' -d '
{
"city": "London",
"country": "England"
}'
You should see the following response confirmation :
{
"_index": "cities",
"_type": "_doc",
"_id": "pquR1oYBQIvdICuNRLuD",
"_version": 1,
"result": "created",
"_shards": {
"total": 3,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
pquR1oYBQIvdICuNRLuD 🤓
You can verify this by running this command :
You should see :
{
"_index" : "cities",
"_type" : "_doc",
"_id" : "pquR1oYBQIvdICuNRLuD",
"_version":1,
"_seq_no":1,
"_primary_term":1,
"found":true
"_source" : {
"city" : "London",
"country" : "England"
}
}
_source field, we will explain more the particular return format of elasticsearch.
Bulk API
The Bulk API in Elasticsearch is a powerful feature that allows you to perform multiple create, update, or delete operations in a single request. It is particularly useful when you need to index or modify a large volume of data efficiently.
This is a quick overview how the Bulk API works:
Request Format: To use the Bulk API, you send an HTTP POST request to the _bulk endpoint of Elasticsearch. The request body contains a series of action and data pairs, called bulk actions. Each action represents a specific operation, such as index, update, or delete, while the data contains the corresponding document or information.Action Line Format: Each action line in the request body consists of two parts: the action type and the action metadata. The action type can be one of the following: index, create, update, or delete. The action metadata typically includes the index name, document ID, and any additional parameters or routing information.Data Format: Following the action line, you provide the actual document data in JSON format. For indexing or updating operations, the data contains the fields and values of the document you want to store or modify. For deletion operations, you don't need to provide any data.Processing the Bulk Request: Elasticsearch processes the bulk request in a batch-oriented manner. It parses the request body, interprets each action line, and executes the corresponding operation on the specified document.Response: Once the bulk request is processed, Elasticsearch returns a response for each action in the request. The response contains information about the success or failure of each operation. It includes a status code, a result line indicating the operation's outcome, and any relevant error messages or details.
Benefits of the Bulk API
- Efficiency: Using the Bulk API significantly reduces the overhead associated with making individual requests for each document operation. It allows you to process large volumes of data in a single request, improving indexing or modification performance.
- Atomicity: The Bulk API ensures atomicity at the operation level. If any action fails during processing, Elasticsearch rolls back all previous operations within the same request. This guarantees data consistency and avoids partial updates.
- Reduced Network Overhead: By combining multiple operations into a single request, the Bulk API minimizes network overhead. This is especially beneficial when indexing or updating a large number of documents distributed across multiple nodes in a cluster.
- Scalability: The Bulk API's batch processing capability allows you to scale your data operations efficiently. You can parallelize and optimize the indexing or modification process, taking full advantage of Elasticsearch's distributed architecture.
In summary, the Bulk API in Elasticsearch enables efficient bulk indexing, updating, or deleting of data by combining multiple operations into a single request. It improves performance, ensures atomicity, reduces network overhead, and supports scalable data processing.
We will use the bulk API in the next section in order to index quickly some data 🤓
Indexing data in Elasticsearch
Create index from json file
Let's create a bash script in order to insert few indices from json files and play with them. First download the json files here and run the following bash script into your terminal :
curl -s -H "Content-Type: application/x-ndjson" -XPOST localhost:9200/receipe/_bulk --data-binary "@receipe.json" &&\
printf "\n✅ Insertion receipe index to elastic node OK ✅ "
curl -s -H "Content-Type: application/x-ndjson" -XPOST localhost:9200/accounts/docs/_bulk --data-binary "@accounts.json"
printf "\n✅ Insertion accounts index to elastic node OK ✅ "
curl -s -H "Content-Type: application/x-ndjson" -XPOST localhost:9200/movies/_bulk --data-binary "@movies.json"
printf "\n✅ Insertion movies index to elastic node OK ✅ "
curl -s -H "Content-Type: application/x-ndjson" -XPOST localhost:9200/products/_bulk --data-binary "@products.json"
printf "\n✅ Insertion products index to elastic node OK ✅ "
curl: a command-line tool for sending HTTP requests and receiving HTTP responses from a server.-s: a flag that tells curl to operate silently, i.e., not to show the progress meter or any error messages.-H"Content-Type: application/x-ndjson": a header that sets the content type of the request to application/x-ndjson. This tells - Elasticsearch that the data being sent in the request body is in NDJSON format.-XPOST: a flag that tells curl to send a POST request to the specified URL.localhost:9200/receipe/_bulk: the URL of the Elasticsearch endpoint to which the request is being sent. In this case, it's the _bulk API for the receipe index on the local Elasticsearch instance running on port 9200.--data-binary "@receipe.json": the request body, which is specified as a binary data file (@ symbol followed by the filename in this case receipe) in NDJSON format. The --data-binary flag tells curl to send the data as is, without any special interpretation.
Overall, this command is sending a bulk request to Elasticsearch to index data contained in the receipe.json file into the receipe index. The data is in NDJSON format, which is a format that Elasticsearch can parse and process efficiently.
Working with Kibana interface
For the rest of this section we will be working with kibana dev tools graphic user interface (GUI). You can run an elastic single node cluster and kibana GUI with the following docker-compose file :
version: '2.2'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.11.1
container_name: elasticsearch
restart: always
environment:
- xpack.security.enabled=false
- discovery.type=single-node
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
cap_add:
- IPC_LOCK
volumes:
- ./elas1:/usr/share/elasticsearch/data
ports:
- 9200:9200
- 9300:9300
networks:
- esnet
kibana:
container_name: kibana
image: docker.elastic.co/kibana/kibana:7.11.1
restart: always
ports:
- 5601:5601
depends_on:
- elasticsearch
networks:
- esnet
networks:
esnet:
driver: bridge
The elasticsearch service uses the official Elasticsearch Docker image version 7.11.1. It sets the container name to elasticsearch and ensures that the container is always restarted if it stops or crashes. It disables X-Pack security and configures Elasticsearch to run as a single-node cluster. It also sets ulimit and cap_add settings to ensure that Elasticsearch has sufficient resources. Finally, it maps the ./elas1 directory on the host to /usr/share/elasticsearch/data inside the container, and exposes ports 9200 and 9300 to allow external access to Elasticsearch.
The kibana service uses the official Kibana Docker image version 7.11.1. It sets the container name to kibana and ensures that the container is always restarted if it stops or crashes. It exposes port 5601 to allow external access to Kibana. It also depends on the Elasticsearch service, so it won't start until Elasticsearch is up and running.
Overall, Kibana is a web-based user interface for Elasticsearch that allows you to interact with Elasticsearch data, run queries, and visualize data in various ways. One of the main advantages of using Kibana is that it provides a user-friendly interface for Elasticsearch, making it easier to explore and analyze data without needing to write complex queries.
It should take a few seconds to launch the installation and then you can go to : http://localhost:5601/app/dev_tools#/console in your browser to see the dev tool console 🤓
You can know verify all our indicies by running the following command :
Mapping
An index mapping in Elasticsearch is a way to define the structure of the documents that will be stored in an index. It specifies the fields that will be part of each document, along with their data types, properties, and settings.
When you create an index in Elasticsearch, you can either provide an explicit mapping or let Elasticsearch infer the mapping automatically based on the first document that is indexed. However, it is generally recommended to define an explicit mapping to ensure that the index has a consistent structure and to avoid unexpected field types or mappings.
An index mapping consists of two main components: field mappings and index settings.
Field mappings define the fields that will be part of each document in the index, along with their data types and properties. For example, a field mapping can define a string field that will store text data, or a numeric field that will store integer or float values. Field mappings can also specify additional settings such as the analyzer to use for text fields, or the format to use for date fields.
Index settings define various aspects of the index, such as the number of shards and replicas, the analysis settings, and the index lifecycle policies. For example, you can specify the number of primary and replica shards that the index will use, or the analyzer to use for text fields in the index.
Overall, an index mapping is an essential component of an Elasticsearch index that allows you to define the structure of the documents that will be stored in the index, along with various settings and configurations that affect the index behavior.
Get index mapping
Let's take a look of our receipe index by tapping this into our kibana dev tool console :
{
"receipe" : {
"mappings" : {
"properties" : {
"created" : {
"type" : "date",
"format" : "yyyy/MM/dd HH:mm:ss||yyyy/MM/dd||epoch_millis"
},
"description" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"ingredients" : {
"properties" : {
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"quantity" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"preparation_time_minutes" : {
"type" : "long"
},
"ratings" : {
"type" : "float"
},
"servings" : {
"properties" : {
"max" : {
"type" : "long"
},
"min" : {
"type" : "long"
}
}
},
"steps" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"title" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
receipe.json document, which has been indexed in Elasticsearch. Here's a breakdown of what each section of the mapping represents:
- The mapping is defined for the receipe index, which contains a single document type.
- The properties section contains all the fields that are part of each document in the index. In this case, the receipe.json document has 7 fields: created, description, ingredients, preparation_time_minutes, ratings, servings, and steps.
-
Each field in the properties section has a specific data type and additional properties that define how the data is indexed and stored. Here are the properties for each field :
created: a date field that can be parsed in the formats "yyyy/MM/dd HH:mm:ss", "yyyy/MM/dd", or as epoch milliseconds.description: a text field that allows full-text search and has an additional keyword sub-field that can be used for exact matching.ingredients: an object field that contains two sub-fields: name and quantity. Both sub-fields are text fields with an additional keyword sub-field.preparation_time_minutes: a long field that stores the preparation time for the recipe in minutes.ratings: a float field that stores the average rating for the recipe.servings: an object field that contains two sub-fields: min and max. Both sub-fields are long fields that represent the minimum and maximum servings for the recipe.steps: a text field that allows full-text search and has an additional keyword sub-field that can be used for exact matching.
Overall, this mapping provides a detailed description of the structure of the receipe.json document, which allows Elasticsearch to index and search the data efficiently. It also provides additional settings and properties that can be used to customize the behavior of the index and optimize its performance.
You can try to print the mapping for the other json documents 🤓
First query
Let's do our first query on the movies index, go to the kibana dev tool interface and copy this query :
movies index in Elasticsearch. It uses the match_all query to match all documents in the index, which is equivalent to a SELECT * statement in SQL.
GET movies/_searchindicates that we want to execute a search request on the movies index. The_searchendpoint is used to search for documents in Elasticsearch we will see this later."query": { "match_all": {} }is the query definition. In this case, we're using thematch_allquery, which matches all documents in the index. The empty object{}inside thematch_allquery means that we're not applying any filters or constraints to the search results.
As you can notice elatic has a strange return format. Let's take a look at this return :
CRUD Operations in Elasticsearch
Elasticsearch supports CRUD (Create, Read, Update, and Delete) operations for manipulating data. Here are some examples of how to perform CRUD operations in Elasticsearch with our json documents :
Create documents
To create a new document in a given index, let's say the receipe index for example, use the following query :
POST receipe/_doc
{
"created": "2022/03/12 12:00:00",
"title": "Chocolate Cake",
"description": "A rich and decadent chocolate cake recipe",
"preparation_time_minutes": 60,
"servings": {
"min": 8,
"max": 10
},
"ingredients": [
{
"name": "flour",
"quantity": "2 cups"
},
{
"name": "sugar",
"quantity": "2 cups"
},
{
"name": "cocoa powder",
"quantity": "3/4 cup"
},
{
"name": "baking powder",
"quantity": "2 teaspoons"
},
{
"name": "baking soda",
"quantity": "2 teaspoons"
},
{
"name": "salt",
"quantity": "1 teaspoon"
},
{
"name": "buttermilk",
"quantity": "1 cup"
},
{
"name": "vegetable oil",
"quantity": "1/2 cup"
},
{
"name": "eggs",
"quantity": "2"
},
{
"name": "vanilla extract",
"quantity": "2 teaspoons"
},
{
"name": "boiling water",
"quantity": "1 cup"
}
],
"steps": "1. Preheat oven to 350 degrees F (175 degrees C). Grease and flour two 9-inch round cake pans.\n2. In a large mixing bowl, combine the flour, sugar, cocoa powder, baking powder, baking soda, and salt. Mix well.\n3. Add the buttermilk, vegetable oil, eggs, and vanilla extract. Beat with an electric mixer on medium speed for 2 minutes.\n4. Stir in the boiling water (the batter will be thin). Pour the batter into the prepared pans.\n5. Bake for 30 to 35 minutes, or until a toothpick inserted into the center of the cakes comes out clean.\n6. Allow the cakes to cool in the pans for 10 minutes, then remove them from the pans and cool completely on wire racks.\n7. Frost and decorate the cakes as desired."
}
You should see this return :
{
"_index" : "receipe",
"_type" : "_doc",
"_id" : "p6va1oYBQIvdICuNjLvj",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 42,
"_primary_term" : 13
}
_index: The name of the index where the document was created, which in this case is "receipe"._type: The document type, which is "_doc" by default in Elasticsearch 7.x and later._id: The unique ID of the newly created document. Elasticsearch automatically generates an ID if you don't provide one explicitly for our case"_id" : "p6va1oYBQIvdICuNjLvj"_version: The version of the document after the create operation. The initial version is always 1. result: The result of the create operation, which is "created" in this case. This indicates that a new document was created._shards: The number of shards involved in the create operation and the number of successful and failed shards. In this case, the create operation involved two shards and was successful on one shard._seq_noand_primary_term: These values are used internally by Elasticsearch to manage replication and consistency. They are not relevant for most users.
Overall, this response confirms that the document was created successfully in the "receipe" index with a unique ID, version 1, and one successful shard.
If we want to create a document with a particular ID just modify the first line of the request by :
It will create a "receipe" document with an ID of9999.
Read documents
Like we have seen before you can run :
Update documents
To update a document in the index, use the following query:
POST receipe/_update/{document_id}
{
"doc": {
"description": "A rich and decadent chocolate cake recipe with layers of buttercream frosting"
}
}
{document_id} with the ID of the document you want to update. This query updates the description field.
Delete documents
To delete a document from the index, use the following query:
Replace {document_id} with the ID of the document you want to delete. This query deletes the specified document from the index.
That's it for the CRUD operations! These are the basic operations you can perform on documents in Elasticsearch. There are many other advanced features and queries you can use to search, analyze, and visualize your data !
Querying Elasticsearch data
Querying in Elasticsearch can seem more complex than a traditional approach like SQL because Elasticsearch is designed to handle unstructured and semi-structured data, whereas traditional databases like SQL are designed to handle structured data.
In Elasticsearch, documents are stored as JSON objects, and each document can have different fields with different data types. This means that searching for information in Elasticsearch requires a different approach than searching for information in a traditional relational database, where the schema is predefined and all data is structured in tables with rows and columns.
Elasticsearch provides a wide range of powerful query options that allow you to search for information in your data in ways that would be difficult or impossible with a traditional relational database. For example, you can use full-text search, fuzzy matching, phrase matching, and regular expressions to search for text data. You can use range queries and geo-queries to search for numerical and geographic data. You can use aggregations to perform statistical analysis on your data. And you can use highlighting and suggesters to provide more user-friendly search results.
In addition, Elasticsearch is designed to be highly scalable and performant, which makes it an excellent choice for applications that require fast and efficient searching of large volumes of data. Elasticsearch can handle massive amounts of data and can be distributed across multiple nodes for even greater scalability and resilience.
Overall, while querying in Elasticsearch may require a different approach than querying in a traditional relational database, the powerful query options and scalability that Elasticsearch provides make it a better choice for information searching and retrieval in many cases.
_search endpoint
The _search endpoint is Elasticsearch's primary endpoint for querying data. It allows you to search one or more indices and retrieve matching documents. The response includes a list of documents that match the query, along with metadata such as the relevance score and any aggregations that were requested.
The main query types available in Elasticsearch are:
Match query
A match query retrieves documents that match a specific keyword or phrase. Here's an example:
Term query
A term query retrieves documents that contain an exact term or phrase. Here's an example:
Range query
A range query retrieves documents that contain a value within a specific range. Here's an example:
GET receipe/_search
{
"query": {
"range": {
"preparation_time_minutes": {
"gte": 60,
"lte": 120
}
}
}
}
Boolean query
A query that combines multiple sub-queries using Boolean operators such as AND, OR, and NOT.
GET receipe/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "chocolate cake"
}
},
{
"range": {
"preparation_time_minutes": {
"gte": 60,
"lte": 120
}
}
}
]
}
}
}
Exists query
An exists query retrieves documents that contain a specific field. Here's an example:
Prefix query
A prefix query retrieves documents that contain a specific prefix in a field. Here's an example:
Wildcard query
A query that retrieves documents that match a specified wildcard pattern in a specified field.
Regexp query: A query that retrieves documents that match a specified regular expression pattern in a specified field.
Fuzzy query
A query that retrieves documents that are similar to a specified search term, accounting for minor spelling errors and variations.
Match Phrase Prefix query
A query that retrieves documents that contain a prefix of a specified phrase in a specified field
Common Terms query
A query that retrieves documents that contain common terms in a specified field, while filtering out terms that are too common.
Query String query
A query that allows you to use advanced search syntax to search for documents in one or more fields.
GET receipe/_search
{
"query": {
"query_string": {
"default_field": "title",
"query": "chocolate AND cake"
}
}
}
Match Phrase query
A query that retrieves documents that contain a specific phrase in a specified field.
Match Boolean Prefix query
A query that retrieves documents that contain a prefix of a specific phrase, using boolean logic to filter out unwanted results.
GET receipe/_search
{
"query": {
"match_bool_prefix": {
"description": "chocolate ca",
"operator": "and"
}
}
}
Terms query
A query that retrieves documents that contain any of a set of specified terms in a specified field.
GET receipe/_search
{
"query": {
"terms": {
"ingredients.name.keyword": ["chocolate", "sugar"]
}
}
}
Nested query
A query that allows you to search within arrays of objects in a specific field.
GET receipe/_search
{
"query": {
"nested": {
"path": "ingredients",
"query": {
"bool": {
"must": [
{
"match": {
"ingredients.name": "chocolate"
}
},
{
"match": {
"ingredients.quantity": "1 cup"
}
}
]
}
}
}
}
}
Geo Distance query
A query that retrieves documents that fall within a specified distance of a geographic location.
GET some_geo_data_index/_search
{
"query": {
"bool": {
"filter": {
"geo_distance": {
"distance": "50km",
"location": {
"lat": 40.715,
"lon": -74.011
}
}
}
}
}
}
More Like This query
A query that retrieves documents that are similar to a specified document.
GET receipe/_search
{
"query": {
"more_like_this": {
"fields": ["title", "description"],
"like": [
{
"_index": "receipe",
"_id": "9999"
}
],
"min_term_freq": 1,
"min_doc_freq": 1
}
}
}
Script query
A query that allows you to write custom scripts to search for documents.
GET receipe/_search
{
"query": {
"script": {
"script": {
"source": "doc['preparation_time_minutes'].value > params.time",
"params": {
"time": 60
}
}
}
}
}
Highlighting
A feature that allows you to highlight matching terms in your search results.
GET receipe/_search
{
"query": {
"match": {
"description": "chocolate"
}
},
"highlight": {
"fields": {
"description": {}
}
}
}
Aggregations
A feature that allows you to perform statistical analysis and grouping of your data.
Sorting
A feature that allows you to sort your search results by one or more fields.
GET receipe/_search
{
"sort": [
{ "preparation_time_minutes": "asc" },
{ "ratings": "desc" }
],
"query": {
"match": {
"title": "cake"
}
}
}
Relevance Score
A score that indicates how well a document matches a query.
Suggesters
A feature that allows you to provide suggestions for misspelled or incomplete search terms.
GET receipe/_search
{
"suggest": {
"title-suggestion": {
"text": "choclate cake",
"term": {
"field": "title"
}
}
}
}
Rescoring
A feature that allows you to re-rank your search results using a different algorithm or set of parameters.
GET receipe/_search
{
"query": {
"match": {
"title": "chocolate cake"
}
},
"rescore": {
"window_size": 50,
"query": {
"rescore_query": {
"match": {
"description": "chocolate"
}
},
"query_weight": 0.7,
"rescore_query_weight": 1.2
}
}
}
These are the main query types available in Elasticsearch. It's important to consult the Elasticsearch documentation for more information and advanced query options.
Aggregation in Elasticsearch
Aggregations are a powerful feature of Elasticsearch that allow you to perform statistical analysis on your data. Aggregations can be used to compute metrics like counts, sums, averages, and histograms, as well as to group data into buckets based on a specified field or set of fields.
Terms Aggregation
A terms aggregation allows you to group your data into buckets based on a specified field. Here's an example of a terms aggregation that groups documents in the "receipe" index by their ratings field:
GET receipe/_search
{
"size": 0,
"aggs": {
"group_by_ratings": {
"terms": {
"field": "ratings"
}
}
}
}
"aggregations": {
"group_by_ratings": {
"buckets": [
{
"key": 3.5,
"doc_count": 3
},
{
"key": 4.0,
"doc_count": 2
},
{
"key": 5.0,
"doc_count": 2
}
]
}
}
Count Aggregation
A count aggregation allows you to count the number of documents that match a specified query. Here's an example of a count aggregation that counts the number of documents in the "receipe" index:
This query will return a response that includes the total number of documents in the "receipe" index:Average Aggregation
An average aggregation allows you to compute the average value of a specified field. Here's an example of an average aggregation that computes the average preparation_time_minutes for all documents in the "receipe" index:
GET receipe/_search
{
"size": 0,
"aggs": {
"average_preparation_time": {
"avg": {
"field": "preparation_time_minutes"
}
}
}
}
Max and Min Aggregation
A max or min aggregation allows you to compute the maximum or minimum value of a specified field. Here's an example of a max aggregation that computes the maximum servings.max value for all documents in the "receipe" index:
GET receipe/_search
{
"size": 0,
"aggs": {
"max_servings": {
"max": {
"field": "servings.max"
}
}
}
}
Similarly, you can use a min aggregation to compute the minimum value of a field.
Date Histogram Aggregation
A date_histogram aggregation allows you to group your data into buckets based on a specified date field. Here's an example of a date_histogram aggregation that groups documents in the "receipe" index by their created field:
GET receipe/_search
{
"size": 0,
"aggs": {
"group_by_created": {
"date_histogram": {
"field": "created",
"interval": "month"
}
}
}
}
This query will return a response that includes the number of documents that fall into each bucket:
"aggregations": {
"group_by_created": {
"buckets": [
{
"key_as_string": "2022-03-01T00:00:00.000Z",
"key": 1646064000000,
"doc_count": 3
},
{
"key_as_string": "2022-04-01T00:00:00.000Z",
"key": 1648742400000,
"doc_count": 1
},
{
"key_as_string": "2022-06-01T00:00:00.000Z",
"key": 1654022400000,
"doc_count": 2
},
{
"key_as_string": "2022-07-01T00:00:00.000Z",
"key": 1656691200000,
"doc_count": 1
}
]
}
}
month. You can also use other intervals like day, hour, minute, second, and so on.
Filter Aggregation
A filter aggregation allows you to filter your data by a specified query before applying any other aggregations. Here's an example of a filter aggregation that only includes documents in the "receipe" index that have a ratings field greater than or equal to 4.0:
GET receipe/_search
{
"size": 0,
"aggs": {
"highly_rated": {
"filter": {
"range": {
"ratings": {
"gte": 4.0
}
}
},
"aggs": {
"group_by_servings": {
"terms": {
"field": "servings.max"
}
}
}
}
}
}
ratings field greater than or equal to 4.0. You can use other filters like match, bool, term, and so on.
Nested Aggregation
A nested aggregation allows you to perform aggregations on nested fields in your documents. Here's an example of a nested aggregation that groups documents in the "receipe" index by their ingredients.name field:
GET receipe/_search
{
"size": 0,
"aggs": {
"group_by_ingredient_name": {
"nested": {
"path": "ingredients"
},
"aggs": {
"group_by_name": {
"terms": {
"field": "ingredients.name"
}
}
}
}
}
}
Wrap-up
Elasticsearch is a powerful search and analytics engine that allows you to store, search, and analyze large amounts of data quickly and in near real-time. Elasticsearch provides a rich set of querying and aggregating capabilities that allow you to search and analyze your data in many different ways.
Queries in Elasticsearch are used to retrieve specific documents or sets of documents that match certain criteria. Elasticsearch supports a wide variety of queries, including term, match, range, wildcard, and fuzzy queries. You can also combine multiple queries using boolean logic and use filters to narrow down your search results.
Aggregations in Elasticsearch are used to compute and summarize statistics about your data. Elasticsearch supports a wide variety of aggregations, including sum, avg, min, max, date histogram, terms, and nested aggregations. Aggregations allow you to group your data into buckets based on one or more fields and compute statistics like counts, averages, sums, and more.
Together, queries and aggregations in Elasticsearch allow you to search and analyze your data in many different ways, giving you valuable insights into your data and helping you make better business decisions.
Queries Exercices for practice
Movies database
Here some queries to practice on the movies database :
- Retrieve all Films titled "Star Wars" directed by "George Lucas" using boolean query.
- Retrieve all Films in which "Harrison Ford" played.
- Retrieve all Films in which "Harrison Ford" played and the plot contains "Jones".
- Retrieve all Films in which "Harrison Ford" played, the plot contains "Jones", but not the word "Nazis".
- Retrieve all Films directed by "James Cameron" with a rank below 1000 using boolean and range query.
- Retrieve all Films directed by "James Cameron" with a rank below 400. (Exact response: 2)
- Retrieve all Films directed by "Quentin Tarantino" with a rating above 5, but not categorized as an action or drama.
- Retrieve all Films directed by "J.J. Abrams" released between 2010 and 2015.
- Retrieve all Films with the word "Star" in the title and a rating above 7.
- Retrieve all Films with the word "Trek" in the title and a rating above 8 released after the year 2000.
Receipe database
- Retrieve all documents in the index.
- Retrieve all documents in the index that have a preparation_time_minutes field greater than or equal to 60.
- Retrieve all documents in the index that have an ingredient with the name "sugar".
- Retrieve all documents in the index that have a servings.min field less than or equal to 4.
- Retrieve all documents in the index that have a ratings field greater than or equal to 4.5.
- Retrieve all documents in the index that have the word "chicken" in the title field.
- Retrieve all documents in the index that have the word "vegetarian" in the description field.
- Retrieve all documents in the index that have the word "bake" in the steps field.
- Retrieve all documents in the index that have a created field after January 1st, 2000.
- Retrieve all documents in the index that have an ingredient with the name "flour" and a servings.max field greater than or equal to 8.
- Compute the average preparation_time_minutes across all documents in the index.
- Group all documents in the index by the number of servings.min and compute the average preparation_time_minutes for each group.
- Compute the sum of preparation_time_minutes for all documents in the index that have the word "chicken" in the title field.
- Group all documents in the index by the servings.max field and compute the average ratings for each group.
- Compute the minimum and maximum preparation_time_minutes for all documents in the index that have an ingredient with the name "sugar".
Account database
- Retrieve all documents in the index with a balance field greater than or equal to 1000.
- Retrieve all documents in the index with a gender field equal to "female".
- Retrieve all documents in the index with an age field between 30 and 40.
- Retrieve all documents in the index with a state field equal to "California".
- Retrieve all documents in the index with an email field containing the word "gmail".
- Retrieve all documents in the index with a registered field after January 1st, 2022.
- Retrieve all documents in the index with a tags field containing the value "neque".
- Retrieve all documents in the index with a phone field starting with the area code "510".
- Retrieve all documents in the index with a isActive field set to true.
- Compute the average balance across all documents in the index.
- Group all documents in the index by the gender field and compute the average balance for each group.
- Compute the sum of balance for all documents in the index with a state field equal to "California".
- Group all documents in the index by the age field and compute the average balance for each group.
- Compute the minimum and maximum balance for all documents in the index with an email field containing the word "quility".
Orders database
- Retrieve all documents in the index.
- Retrieve all documents in the index with a total_amount field greater than or equal to 100.
- Retrieve all documents in the index with a status field equal to "processed".
- Retrieve all documents in the index with a salesman.name field containing the word "Woodruff".
- Retrieve all documents in the index with a sales_channel field equal to "store" and a total_amount field greater than 50.
- Compute the average total_amount across all documents in the index.
- Group all documents in the index by the sales_channel field and compute the sum of total_amount for each group.
- Compute the count of documents in the index with a status field equal to "completed".
- Group all documents in the index by the salesman.name field and compute the average total_amount for each group.
- Compute the minimum and maximum total_amount for all documents in the index with a purchased_at field in the year 2016.