Large Language Model Introduction
Today AI is everywhere and in many aspects of engineering AI has become an essential tool in the toolkit of engineers across various disciplines. But do not be fool by all the AI experts on social media. AI is not just a tool but a transformative technology that is reshaping how engineers work and think. Understanding and leveraging AI is becoming a non-negotiable aspect of engineering professions to ensure they are not left behind as the industry evolves.

Let's begin by talking about Large Language Models, such as the well known ChatGPT, and see how it is work and try to know how to leverage it on our every day job 😎
What is a LLM ?
Large Language Models (LLMs) are a type of artificial intelligence model that specializes in understanding and generating human-like text based on given input.
These models are trained on a vast quantity of text data and learn to predict the next word in a sentence given the previous words. This learning mechanism allows the models to generate meaningful and coherent text that closely resembles human-written text.
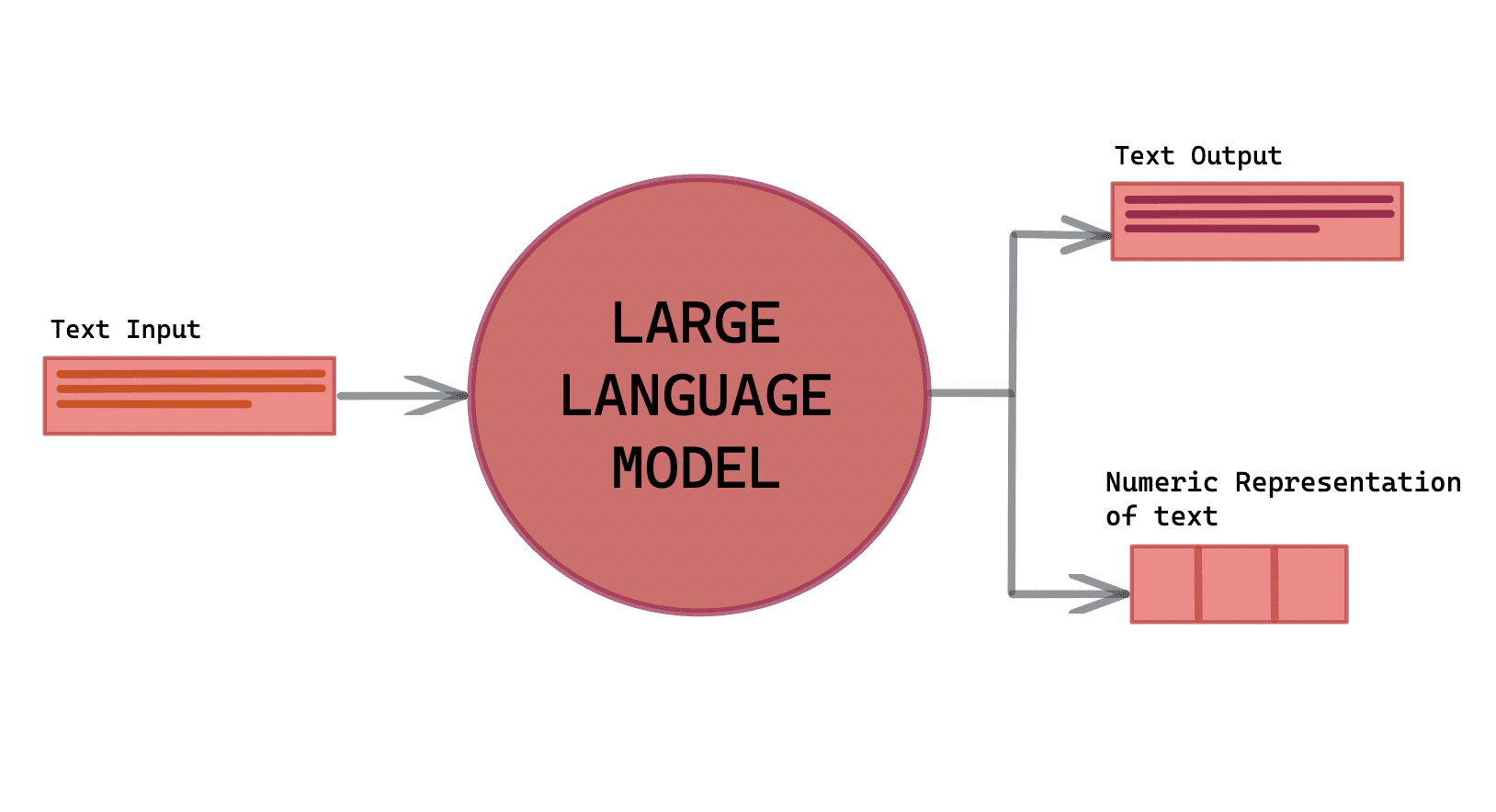
As you may know, LLM have been central in the advance of natural language processing (NLP) area, paving the way for innovations in areas such as conversational agents, translating different languages, generating text and many other things.
Let's explore in this series of articles how a LLM are built, first we will study in detail how the GPT architecture works and how we can replicate this in local.
For this experiment, we will based our work on the excellent article GPT in 60 Lines of NumPy of Jay Mody 😎
History and evolution
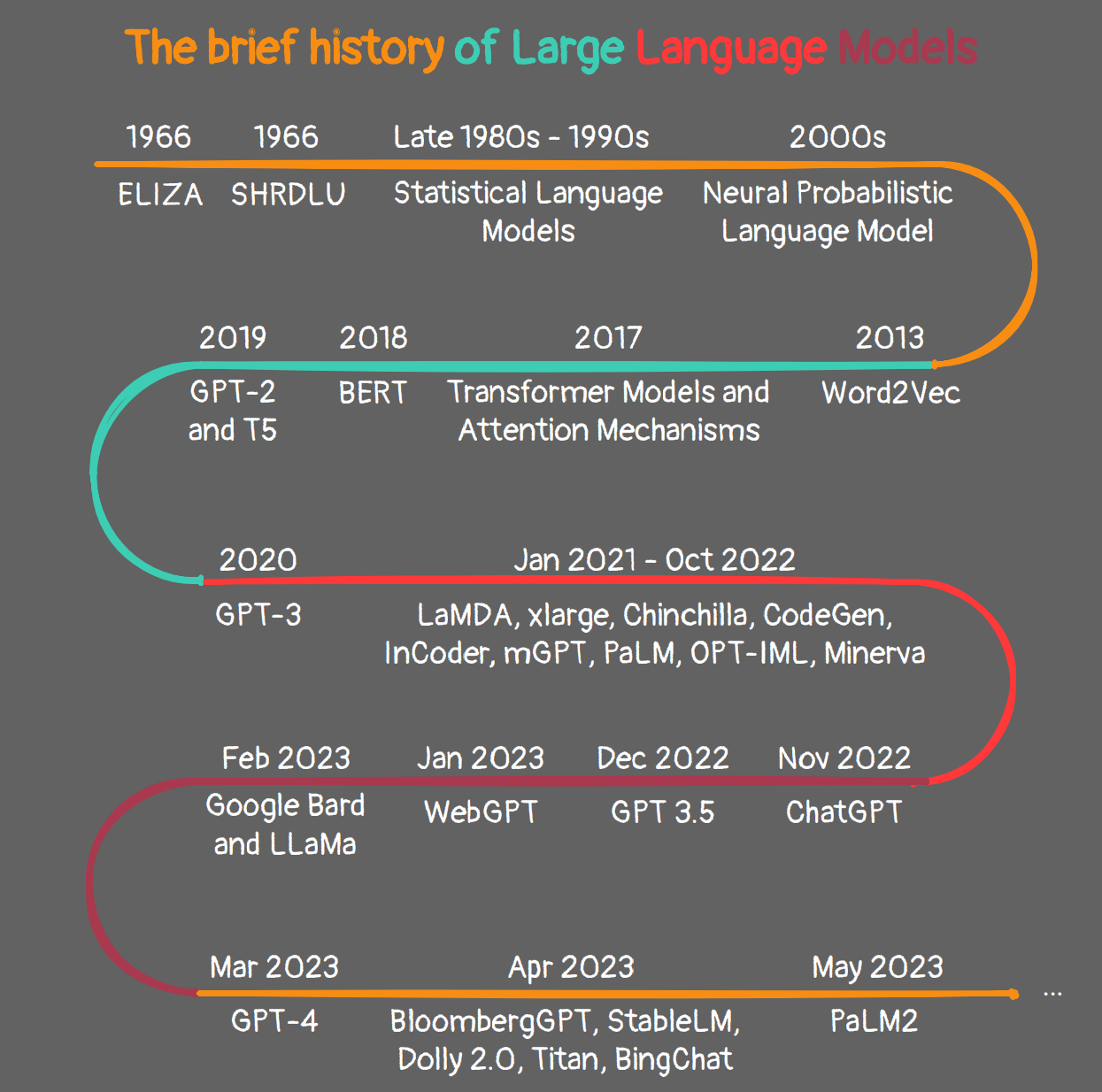
The history of Large Language Models (LLMs) traces back to the 1960s, starting with the development of the first chatbot, Eliza, by MIT researcher Joseph Weizenbaum. Eliza was a basic program that mimicked human conversation through pattern recognition, setting the stage for future research in natural language processing (NLP) and more advanced LLMs.
Significant progress in LLMs was driven by innovations such as the introduction of Long Short-Term Memory (LSTM) networks in 1997, enhancing the capability of neural networks to process larger data sets. Another leap was the launch of Stanford’s CoreNLP suite in 2010, offering tools for complex NLP tasks like sentiment analysis and named entity recognition.
Google Brain, initiated in 2011, provided vast computing resources and advanced features like word embeddings, significantly advancing NLP research. This led to the development of Transformer models in 2017, marking a new era of more sophisticated LLMs, including OpenAI's GPT-3, which laid the groundwork for ChatGPT and other AI applications. More recently, platforms like Hugging Face and BARD have further propelled LLM advancements by offering accessible frameworks for developing LLMs.
GPT
GPT stands for Generative Pre-trained Transformer. It is the first famous LLM basicly it's just a type of neural network architecture based on the Transformer architecture introduced in the paper Attention Is All You Need by Vaswani et al. (2017).
The GPT architecture was introduced in the paper Improving Language Understanding by Generative Pre-Training by Radford et al. (2018).
- Generative: A GPT generates text.
- Pre-trained: A GPT is already trained on lots of text from books, the internet, etc ...
- Transformer: A GPT is a decoder-only transformer neural network.
Indeed GPT was trained on a large corpus of English data in a self-supervised fashion. It was trained on the BooksCorpus (800M words) dataset and the English Wikipedia (2500 M words) dataset, consisting of ~40GB of text data 😳.
I strongly recommand the Jay Alammar's How GPT3 Works article with animation as an excellent introduction to GPTs at a high level.
If you prefer video courses, for me you can not go wrong with 3blue1brown, this is the best GPT explanation I saw so far 😳
Inside GPT input/output logic
This post assumes you are familiar with Python, NumPy, and some basic experience training neural networks.
If you are not, check my others articles on these subjects.
This implementation is missing tons of features on purpose to keep it as simple as possible while remaining complete. The goal is to provide a simple yet complete technical introduction to the GPT as an educational tool.
The GPT architecture is just one small part of what makes LLMs what they are today. All the code for this blog post can be found at github.com/jaymody/picoGPT.
The function signature for a GPT looks roughly like this :
def gpt(inputs: list[int]) -> list[list[float]]:
# inputs has shape [n_seq]
# output has shape [n_seq, n_vocab]
output = # beep boop neural network magic
return output
The input is some text represented by a sequence of integers that map to tokens in the text:
# integers represent tokens in our text, for example:
# text = "not all heroes wear capes":
# tokens = "not" "all" "heroes" "wear" "capes"
inputs = [1, 0, 2, 4, 6]
Tokens are sub-pieces of the text, which are produced using some kind of tokenizer. We can map tokens to integers using a vocabulary :
# the index of a token in the vocab represents the integer id for that token
# i.e. the integer id for "heroes" would be 2, since vocab[2] = "heroes"
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
# a pretend tokenizer that tokenizes on whitespace
tokenizer = WhitespaceTokenizer(vocab)
# the encode() method converts a str -> list[int]
ids = tokenizer.encode("not all heroes wear") # ids = [1, 0, 2, 4]
# we can see what the actual tokens are via our vocab mapping
tokens = [tokenizer.vocab[i] for i in ids] # tokens = ["not", "all", "heroes", "wear"]
# the decode() method converts back a list[int] -> str
text = tokenizer.decode(ids) # text = "not all heroes wear"
In practice, we use more advanced methods of tokenization than simply splitting by whitespace, such as Byte-Pair Encoding or WordPiece, but the principle is the same:
- There is a vocab that maps string tokens to integer indices
- There is an encode method that converts str -> list[int]
- There is a decode method that converts list[int] -> str[2]
The output is a 2D array, where output[i][j] is the model's predicted probability that the token at vocab[j] is the next token inputs[i+1]. For example:
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[0] = [0.75 0.1 0.0 0.15 0.0 0.0 0.0 ]
# given just "not", the model predicts the word "all" with the highest probability
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[1] = [0.0 0.0 0.8 0.1 0.0 0.0 0.1 ]
# given the sequence ["not", "all"], the model predicts the word "heroes" with the highest probability
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[-1] = [0.0 0.0 0.0 0.1 0.0 0.05 0.85 ]
# given the whole sequence ["not", "all", "heroes", "wear"], the model predicts the word "capes" with the highest probability
To get a next token prediction for the whole sequence, we simply take the token with the highest probability in output[-1] :
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
next_token_id = np.argmax(output[-1]) # next_token_id = 6
next_token = vocab[next_token_id] # next_token = "capes"
Taking the token with the highest probability as our prediction is known as greedy decoding or greedy sampling.
Ok, I think you have it now... Generating a single word is cool, but what about entire sentences, paragraphs, etc ... 🤓
Generating text
We can generate full sentences by iteratively getting the next token prediction from our model. At each iteration, we append the predicted token back into the input :
def generate(inputs, n_tokens_to_generate):
for _ in range(n_tokens_to_generate): # auto-regressive decode loop
output = gpt(inputs) # model forward pass
next_id = np.argmax(output[-1]) # greedy sampling
inputs.append(int(next_id)) # append prediction to input
return inputs[len(inputs) - n_tokens_to_generate :] # only return generated ids
input_ids = [1, 0] # "not" "all"
output_ids = generate(input_ids, 3) # output_ids = [2, 4, 6]
output_tokens = [vocab[i] for i in output_ids] # "heroes" "wear" "capes"
This process of predicting a future value (regression), and adding it back into the input (auto), is why you might see a GPT described as autoregressive.
That's pretty much it for the generation process part 🤓 Like I told you before we are by passing on purpose many features, do not hesitate to dig more into the excellent article GPT in 60 Lines of NumPy of Jay Mody if you want the end to end project 😎
Overview of LLM challenges
Ok, now that we've seen how interesting qnd cool LLM tools are, let's look at some of the challenges and opportunities they are facing today 🤓
Costs : money always money ...
The cost of deploying and maintaining LLMs is a significant hurdle for many enterprises. The expenses related to data processing, storage, and the Computational power required for these models can be very large, especially for tiny companies 🤑.
You can take a look at the Stanford’s FrugalGPT paper if you want to have a precise idea of the reality of a LLM costs.
Quantization
Model quantization is an approach to reduce the memory requirements of large neural networks by lowering the precision of their weights. Models such as OpenAI GPT are often substantial in size, defined by their parameter count.

However, a larger parameter count doesn’t necessarily imply better performance. For example, some facebook llama models are optimized for efficiency without requiring massive parameter sizes.
The today's challenge is to build a small LLM who outperform the bigger one on certain tasks, for a complete benchmark you can take a look at the hugging face benchmark who classify the referenced LLM by specific metrics.
Variety of input/format
Handling multiple input formats in Large Language Models (LLMs) is both an exciting opportunity and a challenge, especially as the demand grows for models that can understand diverse data types beyond simple text. Here are some of the key challenges associated with supporting multiple input formats in LLMs:
Data Representation and Encoding
Different data types, such as text, images, audio, and structured data (like tables), have their unique structures and encoding schemes. For instance, text can be tokenized, while images might need to be represented as pixel grids or features. Converting these formats into a form that the model can process—typically a sequence of tokens—requires specialized encoding techniques.
Encoders for each input type (e.g., convolutional neural networks for images, transformers for text) are often required to generate a uniform representation. Ensuring this uniformity across types can be computationally expensive 💸
Architectural Complexity
Handling different input formats often necessitates changes in the model architecture to accommodate different types of encoders. For example, some multimodal LLMs may combine convolutional layers for image processing with transformer layers for text.
Maintaining architectural flexibility and efficiency is challenging, especially as the model grows to support additional formats. This can increase both the model's size and its computational requirements, which makes deployment more resource-intensive 🥲
Developing an LLM to handle multiple input formats effectively requires a combination of advanced data processing, flexible model design, and careful training and validation on multimodal datasets.
The rapid advances in open source tools and techniques like open-llm-initiative/open-message-format are pushing these models closer to overcome these challenges fully.
Adversarial Attacks 🏴☠️
Adversarial attacks are a major concern for LLMs. These attacks involve manipulating input data to deceive the model into producing incorrect or misleading outputs.
Try to defeat Gandalf and see how easily you can hack an LLM 🥷
Data quality and availability
Another significant challenge facing LLMs is the quality and availability of training data. High-quality data is essential for training accurate models, but it can be scarce or expensive to obtain. This challenges the ability of LLMs to generalize well to unseen data.
LLM biais
Like every other models, LLM are subject to biais. Bias refers to systematic errors or prejudices in the predictions of LLMs, often influenced by the characteristics of the training data.
These biases, influenced by training data, can result in unfair predictions and social consequences. Bias occurs when certain groups are underrepresented or stereotyped in the data or when model design choices introduce unintentional prejudice. Such biases can reinforce stereotypes, perpetuate discrimination, and spread misinformation 🥲.
To address this, a combination of technical, ethical, and regulatory approaches is necessary. Methods include debiasing algorithms, fairness-aware training, and inclusive data practices. Regular testing can help identify biases in applications like chatbots.
For a deeper lecture you can take a look at the excellent article LLM Bias: Understanding, Mitigating and Testing the Bias in Large Language Models Quickly learn about Bias in LLMs by Kostya
Interpretability and Explainability
Finally, there is an increasing need for LLMs to provide more interpretable and explainable results. As these models become more pervasive in critical applications such as healthcare and finance, it's essential to understand how they arrive at their conclusions.
LLM Web UI Selection
Ollama & AnythingLLM integration
Let's try to deploy our own LLM in local with my favourite clean UI 🥰 and Ollama backend with Cloudron in order to have a secure deployement with SSL and some Role-Based Access Control (RBAC).
Docker deployment
In order to facilitate our deployment we will use a docker-compose file like bellow here :
version: '3.8'
services:
ollama:
image: ollama/ollama
container_name: ollama
volumes:
- ollama_data:/root/.ollama
ports:
- "11434:11434"
environment:
- NVIDIA_VISIBLE_DEVICES=all
deploy:
resources:
reservations:
devices:
- capabilities: ["gpu"]
anythingllm:
image: mintplexlabs/anythingllm
ports:
- "3001:3001"
volumes:
- ${STORAGE_LOCATION}:/app/server/storage
- ${STORAGE_LOCATION}/.env:/app/server/.env
environment:
- STORAGE_DIR=/app/server/storage
depends_on:
- ollama
volumes:
ollama_data:
Now you should have the following GUI here on your local machine. For me it is already deployed on Cloudron with the proxy app cloudron service but it is the same thing in your local machine :

Load LLM models
Now you can load some models according to the Ollama documentation with this command, let's try to load the llama2-uncensored model for example here :
You can also add gguf model for testing. Just create a file named Modelfile, with a FROM instruction with the local filepath to the model you want to import.
Then create the model in Ollama
you should see this output :
transferring model data
creating model layer
using already created layer sha256:6db6207024eea05cc46b71276780e297584a859c671635876b5b8a3048ed9b7d
writing layer sha256:2a3477847351b95ce85dbfa199e9a1b2b827df958d0707f1ca13fc54fb2cb1c4
writing manifest
success
Then run the model
More details with the official documentation here, you can also enjoy the REST API from Ollama server and easily curl models like
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt":"Why is the sky blue?"
}'
That's it, you have a local LLM running with a nice GUI 🥳
Ollama and Streamlit
Let's code a simple Streamlit app to chat with a PDF (upload your PDF up to 200MB) with Ollama and LangChain to ingest and chat with it 😎

#!/bin/env python3
import os
import tempfile
import streamlit as st
from langchain_community.vectorstores import Chroma
from langchain_community.chat_models import ChatOllama
from langchain_community.llms import Ollama
from langchain_community.embeddings import FastEmbedEmbeddings
from langchain.schema.output_parser import StrOutputParser
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema.runnable import RunnablePassthrough
from langchain.prompts import PromptTemplate
from langchain.vectorstores.utils import filter_complex_metadata
class ChatPDF:
vector_store = None
retriever = None
chain = None
def __init__(self):
self.model = Ollama(model="mistral", base_url="http://localhost:11434", verbose=True)
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=100)
self.prompt = PromptTemplate.from_template(
"""
<s> [INST] You are an assistant for question-answering tasks. Use the following pieces of retrieved context
to answer the question. If you don't know the answer, just say that you don't know. [/INST] </s>
[INST] Question: {question}
Context: {context}
Answer: [/INST]
"""
)
def ingest(self, pdf_file_path: str):
docs = PyPDFLoader(file_path=pdf_file_path).load()
chunks = self.text_splitter.split_documents(docs)
chunks = filter_complex_metadata(chunks)
vector_store = Chroma.from_documents(documents=chunks, embedding=FastEmbedEmbeddings())
self.retriever = vector_store.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={
"k": 3,
"score_threshold": 0.5,
},
)
self.chain = ({"context": self.retriever, "question": RunnablePassthrough()}
| self.prompt
| self.model
| StrOutputParser())
def ask(self, query: str):
if not self.chain:
return "Please, add a PDF document first."
return self.chain.invoke(query)
def clear(self):
self.vector_store = None
self.retriever = None
self.chain = None
st.set_page_config(page_title="ChatPDF")
def message(text, is_user, key):
"""Displays a message in the Streamlit app with a basic HTML styling."""
if is_user:
st.write(f"<div style='margin: 10px; padding: 10px;'><b>You:</b> {text}</div>", unsafe_allow_html=True)
else:
st.write(f"<div style='margin: 10px; padding: 10px;'><b>Assistant:</b> {text}</div>", unsafe_allow_html=True)
def display_messages():
st.subheader("Chat")
for i, (msg, is_user) in enumerate(st.session_state["messages"]):
message(msg, is_user=is_user, key=str(i))
st.session_state["thinking_spinner"] = st.empty()
def process_input():
if st.session_state["user_input"] and len(st.session_state["user_input"].strip()) > 0:
user_text = st.session_state["user_input"].strip()
with st.session_state["thinking_spinner"], st.spinner(f"Thinking"):
agent_text = st.session_state["assistant"].ask(user_text)
st.session_state["messages"].append((user_text, True))
st.session_state["messages"].append((agent_text, False))
def read_and_save_file():
st.session_state["assistant"].clear()
st.session_state["messages"] = []
st.session_state["user_input"] = ""
for file in st.session_state["file_uploader"]:
with tempfile.NamedTemporaryFile(delete=False) as tf:
tf.write(file.getbuffer())
file_path = tf.name
with st.session_state["ingestion_spinner"], st.spinner(f"Ingesting {file.name}"):
st.session_state["assistant"].ingest(file_path)
os.remove(file_path)
def page():
if len(st.session_state) == 0:
st.session_state["messages"] = []
st.session_state["assistant"] = ChatPDF()
st.header("ChatPDF")
st.subheader("Upload a document")
st.file_uploader(
"Upload document",
type=["pdf"],
key="file_uploader",
on_change=read_and_save_file,
label_visibility="collapsed",
accept_multiple_files=True,
)
st.session_state["ingestion_spinner"] = st.empty()
display_messages()
st.text_input("Message", key="user_input", on_change=process_input)
if __name__ == "__main__":
page()
Damn cool no 😎
Running your own local LLM and chat with your PDF, just remerber that just one year ago in 2023 it was not even imaginable to do this 😳
More LLM cool Web interfaces
Of course stramlit applications are basics, you can also rely on pre build interfaces from the community here :
- Amazing clean UI from Hugging Face
- LLM AUTOMATIC111 - supports any model format and has many extensions
- Clean UI, focuses on GGUF format love this one 🥰
- Web Ui with PDF, stable diffusion and web search integration
- Web Ui for files ingestion, supports many file formats
- Basic UI that replicated ChatGPT
- Basic UI that replicated ChatGPT with PDF integration
- ChatGPT like UI with easy way to download models
Every tools are cool in my opinion depeding on your needs and use cases, just take your time to read them all
Faster, harder and stronger serving with vLLM
Serving locals LLMs faster, harder and stronger with vLLM. vLLM is a high-performance LLM serving and inference library designed to make the deployment of LLMs more efficient and scalable.
Its main goal is to optimize latency and throughput, particularly for applications that require real-time or high-frequency interactions with LLMs. vLLM achieves these improvements by using optimized memory management and specialized scheduling for GPU or CPU resources, allowing it to serve multiple requests more effectively without duplicating data or overloading memory.
Key Features of vLLM: - Efficient Memory Management: vLLM uses techniques like continuous batching and tensor parallelism to minimize memory usage, enabling faster inference and lower costs. - High Throughput: It is designed to handle multiple simultaneous queries by optimizing how model weights and computations are shared across requests. - Flexibility and Scalability: vLLM supports various model architectures and configurations, making it adaptable for different LLM applications. - Lower Latency: By managing hardware resources efficiently, vLLM reduces response times, which is crucial for real-time applications.
Difference between vLLM and Ollama
-
vLLM is aimed at maximizing performance, scalability, and efficiency in a cloud or server environment, making it ideal for enterprise-grade applications needing high throughput.
-
Ollama targets privacy-conscious users and developers who prefer to run models locally or within private infrastructure, making it suitable for smaller-scale applications or use cases requiring data privacy.
vLLM is oriented towards high-performance, scalable LLM serving with optimized memory usage, while Ollama prioritizes user-friendly, local model deployment and data privacy.
The choice between Ollama and vLLM depends on your specific needs: if you need high concurrency and scalability, vLLM is a strong option. For local or privacy-focused deployments, Ollama is ideal.
Gen AI plug and play stack
If you just want to play with Gen AI and models without having to install a complete env, you can take a quick look at the excellent git repo AI Local gen stack
Wrap it up
In conclusion, we can say that Large Language Models (LLMs) have become transformative tools in the software engineering world, offering powerful capabilities across various applications. However, their effective deployment requires addressing challenges like model size, bias, efficiency, and optimization as we have seen through this article 🤓.
Techniques such as model quantization and serving plateforms like vLLM and Ollama demonstrate how LLMs can be tailored for diverse use cases, from high-performance, scalable applications to privacy-focused, local deployments.
As LLM technology continues to evolve every day, thoughtful strategies for managing these models will be essential to harness their potential responsibly and effectively.
Hope you've learn a thing or two, happing coding to you 🤗